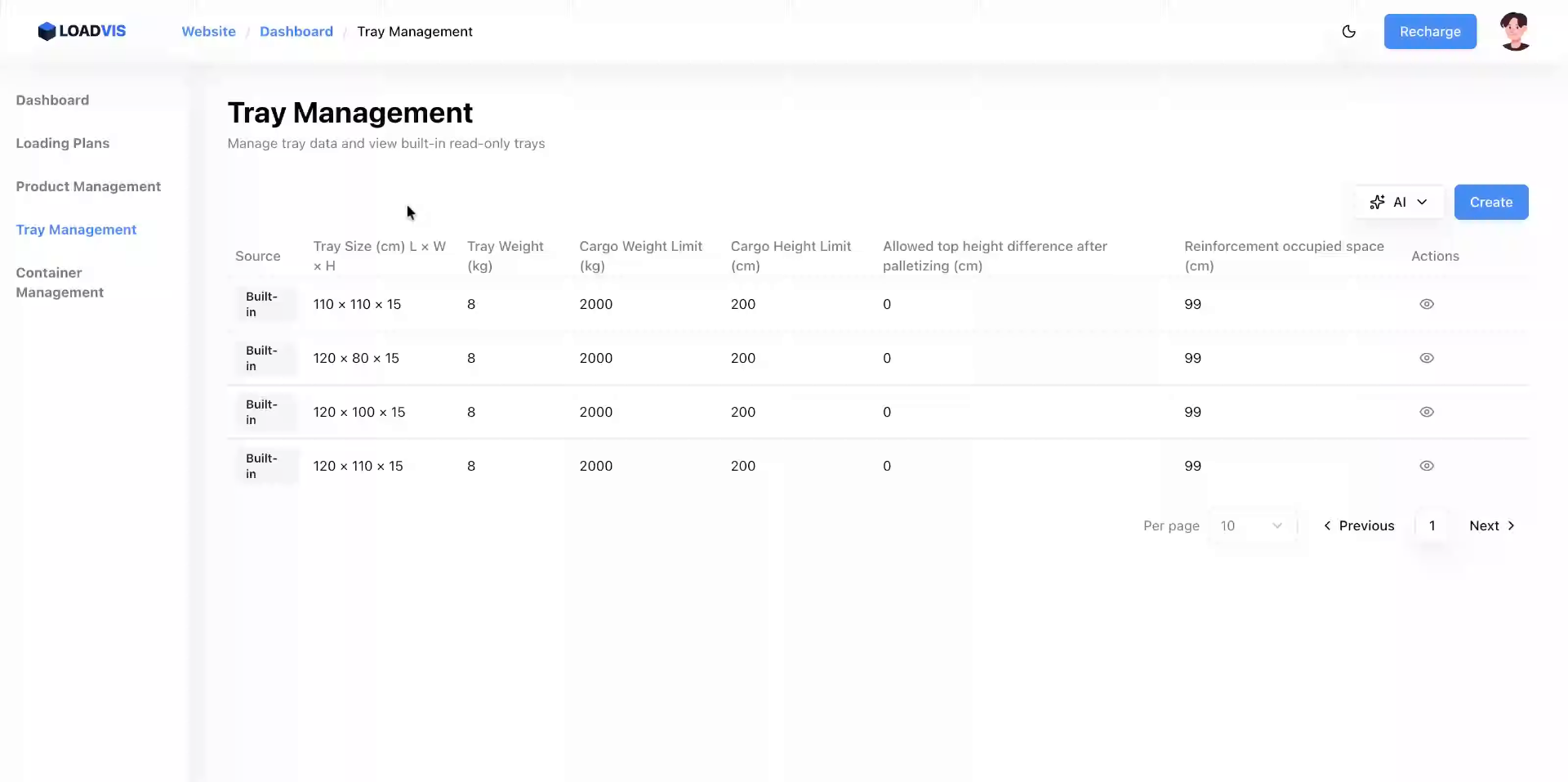
Szenario-Rückblick: Gewichtsverteilung und operative Risiken bei gemischten Palettenladungen
Volumenfüllung sieht auf dem Monitor perfekt aus. In der Praxis kippt die Ladung aber gerne. Warum? Weil Planungsquoten fast immer kubische Werte optimieren, während die Physik sich weigert, mitspielen zu wollen. Wir rechnen mit Kubikmetern. Der Gabelstaplerfahrer rechnet mit Schwerpunktlagen, Reibungskoeffizienten und dynamischer Scherbelastung. Das ist keine Semantik. Das ist der Unterschied zwischen einer sauberen Lieferroute und einem nachts um drei angerufenen Disponenten. Die korrekte Parametrisierung von Ladungsträgern ist kein UI-Spielchen. Sie ist operatives Risikomanagement. Punkt.
Die Kluft zwischen Volumetrie und Physik
Wir kennen die Metriken. Packdichten. Füllgrade. Wenn ein Algorithmus nur nach Raumverbrauch optimiert, entstehen schwere Basen mit instabilen Kopflasten. Ein Container rollt nicht, weil die Software sagte "98% Auslastung". Er rollt, weil die Schwerpunkthöhe fünfzehn Zentimeter zu hoch lag und die Seitenwand beim Kurvenfahren nachgab. Ich habe Szenarien dokumentiert, wo nominale Maximalwerte aus starren Herstellerdatenblättern als hartes Limit hinterlegt wurden. In der Realität schwankt das Trägergewicht durch Holzfeuchte, Produktionsabweichungen bei Kunststoff oder Kartonagen-Toleranzen. Die Software akzeptiert den Idealwert. Die Rampe akzeptiert die reale Fracht. Kollision.
Wenn die Datenquelle statisch bleibt, ignoriert sie produktspezifische Gewichtsschwankungen komplett. Fragile Stapelgrenzen werden oft als weiche Warnung behandelt. Sie müssten harte Stopps sein. Hier setzt die eigentliche operative Lücke an. Wir müssen die algorithmische Verteilung validieren, bevor die Ladung überhaupt den LKW-Boden berührt. Oder wir zahlen die Rechnung für das aufwendige Nachladen.
Automatisierung, Datenkonsistenz und die Grenze der Simulation
Textbasierte Spezifikationen zu parsen klingt nach Routine. Ist es auch, solange die Struktur stimmt. Aber unstrukturierte Lieferantenangaben brechen Parsing-Routinen schneller als ein schlecht abgesicherter API-Endpoint. Die automatische Übernahme von Abmessungen, Eigengewicht und Frachtlimits funktioniert nur, wenn die Eingabedaten konsistent sind.
Das System liest. Ordnet zu. Speichert. Doch eine erkannte Toleranz von fünf Zentimetern Oberhöhe ist nur eine Zahl, bis sie mit lokalen Verladekapazitäten kollidiert. Manuelle Prüfungen, die nötig sind, umfassen hier nicht nur das Abhaken von Checkboxen. Sie erfordern den Abgleich von physikalischen Realitäten. Wenn ein Produkt eine maximale Stapelhöhe von 180 Zentimetern hat, der LKW aber eine Innenhöhe von 230 Zentimetern bietet, rechnet die Software mit Spielraum. Der Fahrer sieht nur die Ladung, die beim Bremsen rutscht. Die Software kennt die Bodenbeschaffenheit der Zielrampe nicht.
Fehlerszenarien: Wenn die Algorithmik die Realität ignoriert
Gegenbeispiel aus der Praxis: Eine gemischte Charge mit Hydraulikaggregaten oben und leeren Kunststoffpaletten unten. Volumetrisch passt alles. Statistisch sogar. Die Schwerpunktverlagerung liegt außerhalb der sicheren Toleranz. Die Simulation zeigt rote Warnbereiche. Die Planungsfreigabe erfolgt trotzdem, weil die Warnung überstimmt wurde. Kostenintensiv. Gefährlich.
Die korrekte Parametrisierung definiert explizite Gewichts- und Höhentoleranzen. Keine weichen Limits. Keine "ungefähren" Werte. Manuelle Prüfungen, die nötig sind, müssen produktspezifische Fragilität berücksichtigen. Ein Karton mit 1.200 kg Tragkraft hält theoretisch. Praktisch? Wenn die Bodenwelle der Rampe nur leicht uneben ist, überträgt sich die Scherbelastung ungleichmäßig. Das Material gibt nach. Der Stack kippt. Die Erstellung von Verladeleitfäden hilft operativ weiter. Aber ein PDF rettet keine schlecht konfigurierte Basis. Sie müssen die Datenquelle bereinigen. Stammdatenabgleich ist keine einmalige Aufgabe. Sie ist ein kontinuierlicher Loop.
Workflow-Realität: Stammdatenpflege und Löschlogik
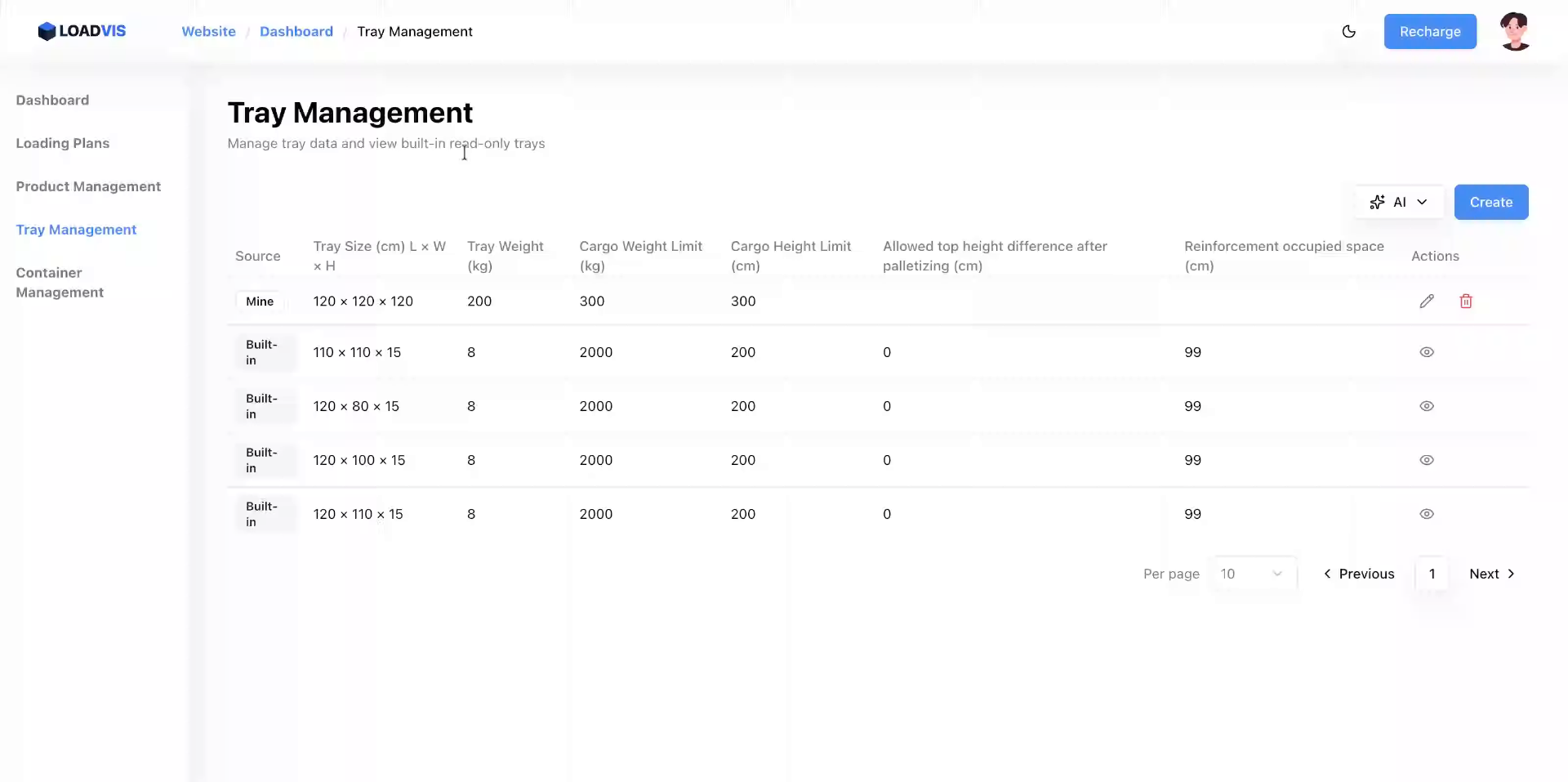
Die Automatisierung beschleunigt. Sie eliminiert aber keine physikalischen Gesetze. Wenn Sie neue Trägerdatensätze anlegen, sei es über Texterkennung oder manuelle Eingabe, prüfen Sie die Verstärkungsfreiabstände. Prüfen Sie die Bodenkontaktflächen. Ignorieren Sie den Kontext nicht.
Ein häufiger Fehler in produktiven Umgebungen: Man überschreibt bestehende Limits, weil ein neuer Lieferant leicht abweichende Abmessungen angibt. Die Datenbank wird kontaminiert. Die nächste Planung läuft mit alten Werten, bis jemand die Detailansicht öffnet und korrigiert. Löschen und Bereinigen gehören genauso zur Routine wie das Anlegen. Ein zweistufiger Bestätigungsmechanismus verhindert versehentlichen Datenverlust. Er zwingt zur bewussten Prüfung.
Und genau hier liegen die Grenzen der Planungswerkzeuge. Software simuliert unter idealen Bedingungen. Sie weiß nicht, ob das Holz der Palette gesplittert ist oder ob der LKW-Boden rutschige Reste von einer vorherigen Tour aufweist. Manuelle Prüfungen, die nötig sind, finden immer an der Schnittstelle zwischen Bildschirm und Rampe statt. Ohne sie bleibt die Simulation ein schönes Gedankenexperiment.
Abschluss
Planungsmetriken optimieren Volumen. Die Physik optimiert Stabilität. Diese Diskrepanz lässt sich nicht wegkonfigurieren. Sie muss gemanagt werden. Durch explizite Toleranzen. Durch harte Validierung. Durch das Eingeständnis, dass Algorithmen nur so gut sind wie die Daten, die sie füttern. Wenn die Gewichtsverteilung schief läuft, rettet kein UI-Makeover. Nur korrekte Stammdaten. Und eine Kultur, die operative Validierung nicht als Zeitverlust, sondern als notwendige Versicherung begreift. Prüft die Daten. Ladet erst dann.