托盘限高与加固间隙配置失真:为何高容积率方案总在装卸口翻车?
92%的体积利用率。 很漂亮。
可现实往往会在装卸口前甩开一个冰冷的耳光。 上周跟进的那票出口杂货,求解器给出的排布方案堪称严丝合缝。嵌套紧密,载重分布也显得极为克制。但现场情况呢。叉车的货叉刚探过去,就听见底部货物跟托盘底梁发生硬性摩擦的声音。超了两厘米。就是这两厘米,直接卡死了平稳插入的动线。外层缠绕膜受力不均,底层微倾斜的迹象肉眼可见。去处理拆垛重码的工作。发车计划顺延四个小时。
症结根本不在求解器的数学模型。 输入层早就偏航了。系统里躺着的托盘模型,属于脱离工况的理想几何体。而仓库里实际流转的托盘,是承载物理磨损与操作公差的载体。包装公差、缠绕膜叠加厚度、托盘长期周转后的微量形变,在多层堆叠的力传导路径上,会被极大程度上地放大成结构性的倾覆风险。 必须把物理世界的粗糙度,前置到数字建模的初始阶段。
一、 为什么这类问题总被低估?
这类翻车事故的缘由,往往被习惯性归咎为“现场操作不规范”。这种归因过于偷懒。主要原因囊括了三个维度的认知错位。
标准件思维的惯性绑架。 很多人直接选用系统内置的 1200×1000 规格模板。尺寸一旦固化,参数就被视作铁律。他们忽略了不同批次板材的承重衰减曲线。底部横梁的间距公差也没有被纳入考量。实际加固工艺所占用的物理空间,更是被习惯性抹除。
约束条件的隐性特征被忽略。 限高从来不是静态的绝对数值。它是一段动态的净空区间,其中必须涵盖叉车臂抬升所需的余量。加固间隙也不是图纸上的视觉留白。它直接牵扯到重心投影的偏移幅度与堆叠自稳性的临界值。求解器只会机械地读取输入端塞进去的数字。物理常识所构建的容错边界,它不会自动识别。
前置校验环节的缺失。 操作人员常常把开展托盘配置的管理工作视作一次性的建档动作。等到排布结果出现干涉,才开始进行方案顺序的调整,或者盲目切换容器规格。这恰恰跳过了最底层的基准参数校准工作。数据源头一旦被污染,后续的迭代只会陷入越改越乱的死循环。
二、 关键操作映射:从模板到物理约束的校准
决定排布方案能否落地执行的核心操作,并不在“点击计算”的那一瞬间。建档阶段的参数映射与结构化转译,才是真正卡住执行命脉的闸门。
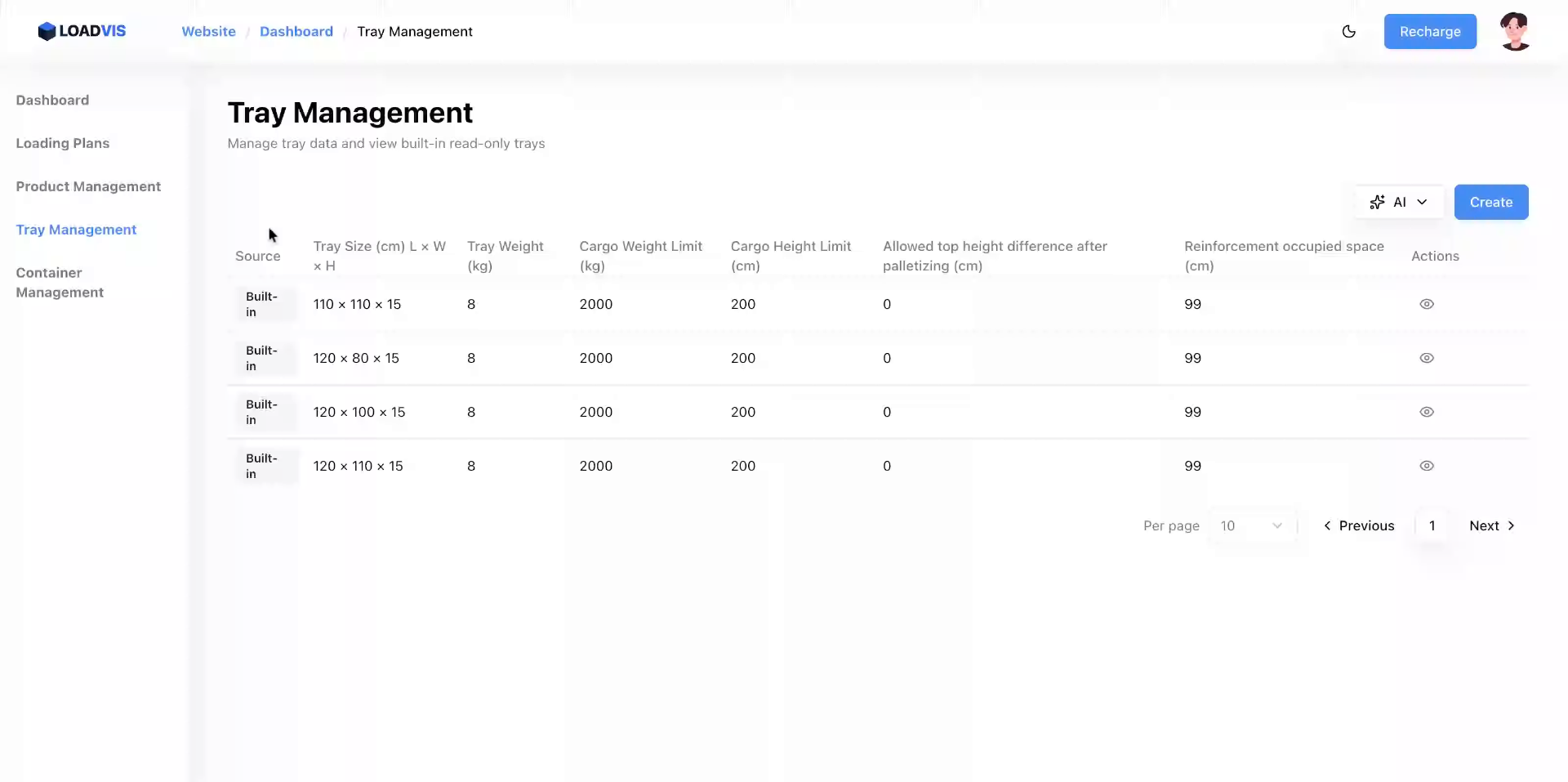
第一步:开展规格详情的交叉核对工作。
你需要进入托盘管理列表区域。针对目标条目,直接点击“查看”按钮。
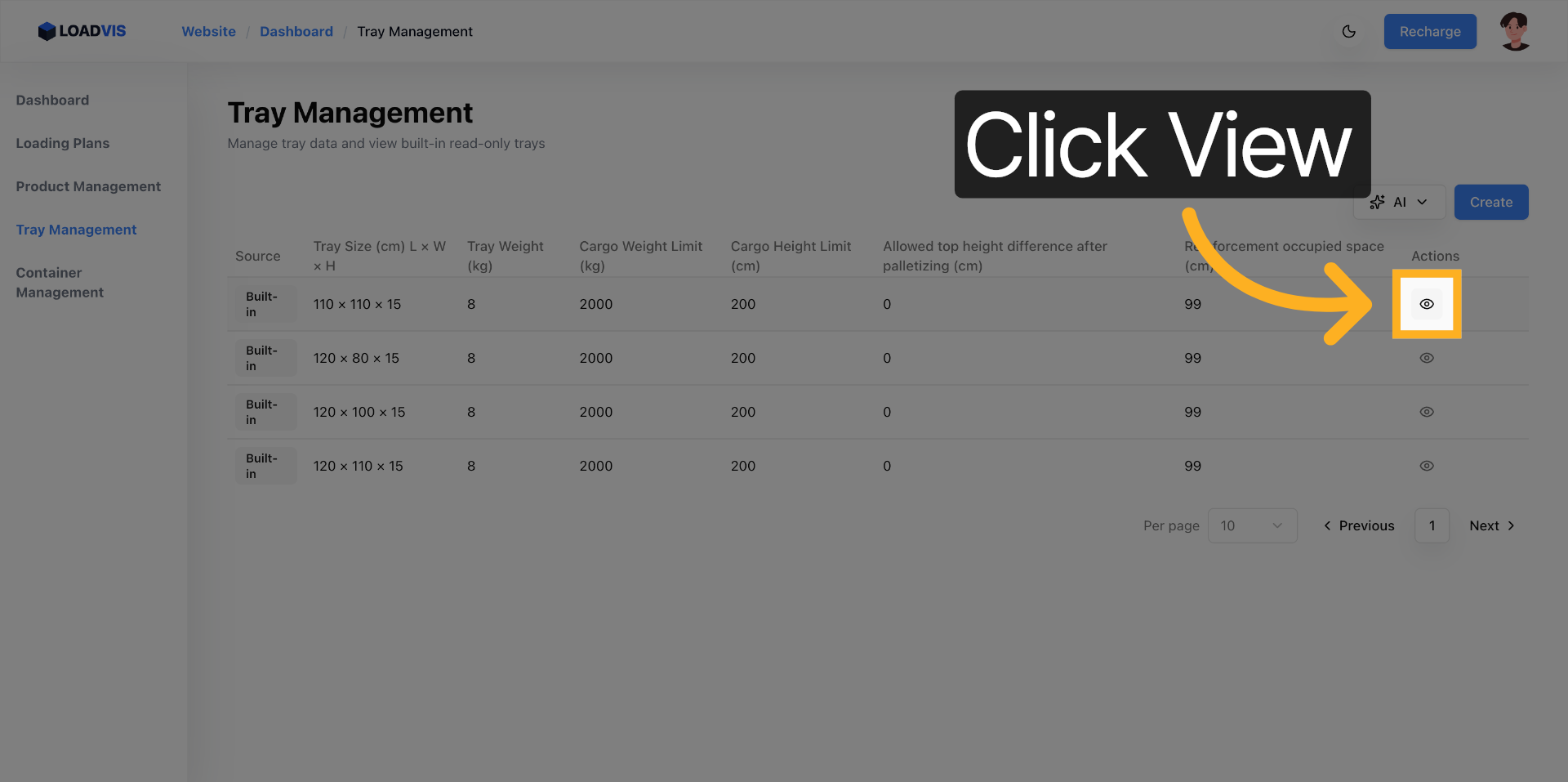 展开的面板会呈现完整的尺寸参数、负载限制以及高度约束字段。这里的工作重心,必须放在确认当前模板的“货物限重”、“货物限高”与“顶层高度差”这三项核心指标上。这是校验输入数据是否契合现场工况的第一道物理屏障。要是跳过此步直接进行装箱计划的构建,那就等于让算法在数据盲区里开展盲目求解。核对完毕之后,记得点击“关闭”把面板收起,返回列表概览。
展开的面板会呈现完整的尺寸参数、负载限制以及高度约束字段。这里的工作重心,必须放在确认当前模板的“货物限重”、“货物限高”与“顶层高度差”这三项核心指标上。这是校验输入数据是否契合现场工况的第一道物理屏障。要是跳过此步直接进行装箱计划的构建,那就等于让算法在数据盲区里开展盲目求解。核对完毕之后,记得点击“关闭”把面板收起,返回列表概览。
第二步:对加固间隙与限高阈值进行精确修正。
在编辑模式下激活表单的写入权限。
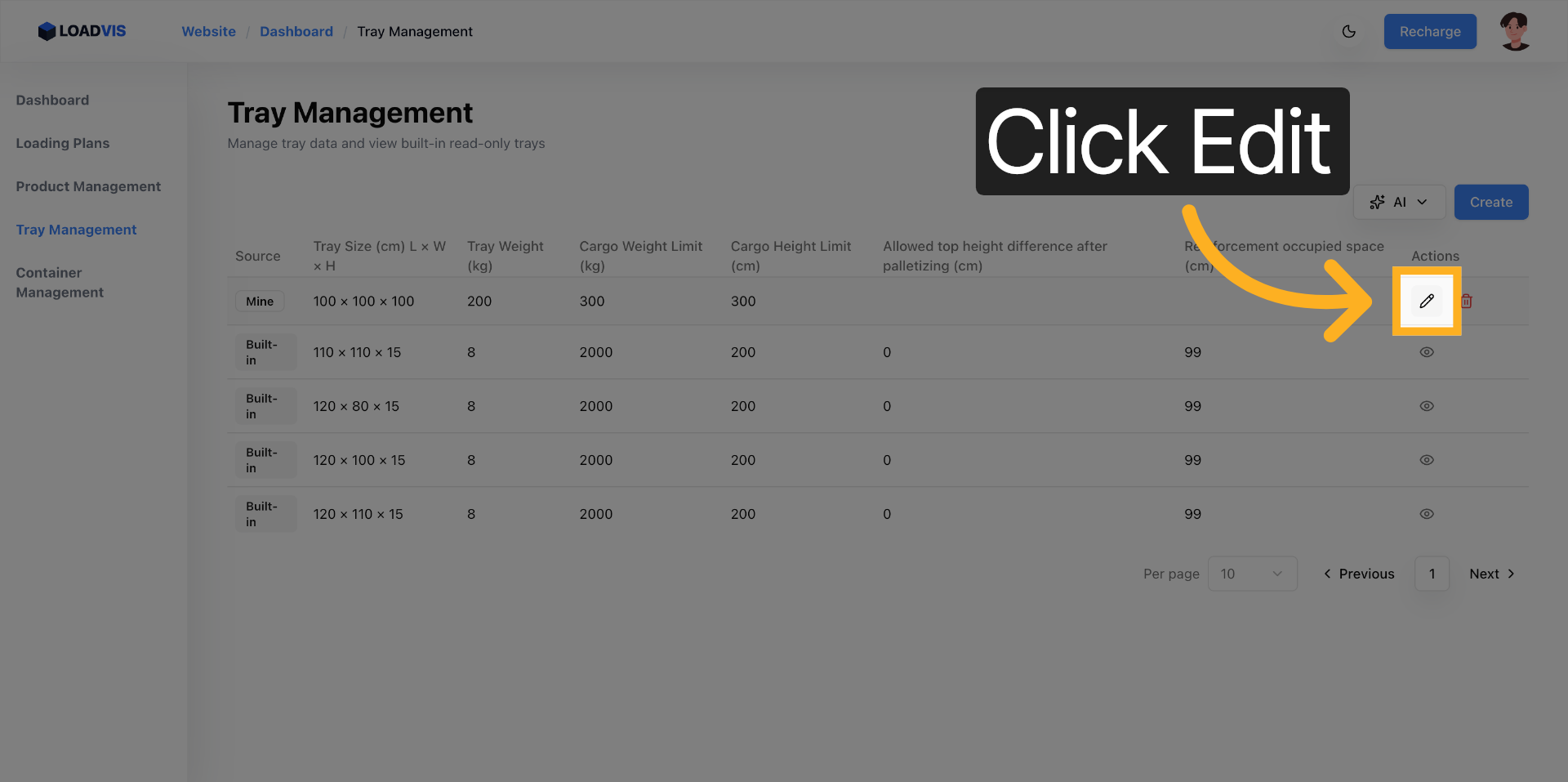 影响执行安全性的决定性因素,从来不是长宽的基础数值。关键在于加固占位空间以及顶层高度差的字段录入。求解器会依赖这些预置参数去开展实际可用装载体积的演算,并且在空间排布过程中,自动去进行重心越界风险的规避处理。在托盘宽度字段中输入数值的时候,必须确保输入精度完全契合实物公差。
影响执行安全性的决定性因素,从来不是长宽的基础数值。关键在于加固占位空间以及顶层高度差的字段录入。求解器会依赖这些预置参数去开展实际可用装载体积的演算,并且在空间排布过程中,自动去进行重心越界风险的规避处理。在托盘宽度字段中输入数值的时候,必须确保输入精度完全契合实物公差。
 修改动作必须走完完整的确认流程。这是为了防止误操作直接覆盖历史有效的基准配置。保存之后,模板的约束逻辑才算真正完成对齐。
修改动作必须走完完整的确认流程。这是为了防止误操作直接覆盖历史有效的基准配置。保存之后,模板的约束逻辑才算真正完成对齐。
第三步:进行动态迭代的参数复核。
借助 AI 创建功能,系统可以把非结构化的文本描述快速提取并转化为托盘的基础参数。
 提取过程虽然迅捷,但物理比对的环节绝对不可以被省略。要是更换了包装材料,比如从标准瓦楞纸箱切换为木质外框,或者增加了四角护角的绑扎工艺,就必须同步去更新模板当中的膨胀系数与间隙字段。旧模板如果不进行及时清理或者修正,就会直接污染后续生成的新计划。
提取过程虽然迅捷,但物理比对的环节绝对不可以被省略。要是更换了包装材料,比如从标准瓦楞纸箱切换为木质外框,或者增加了四角护角的绑扎工艺,就必须同步去更新模板当中的膨胀系数与间隙字段。旧模板如果不进行及时清理或者修正,就会直接污染后续生成的新计划。
三、 错误做法 vs 更稳妥做法
现场执行时常见的认知断层,往往可以凭借对比来迅速定位。以下是对照维度的拆解。
| 维度 | 经验主义的路径(高风险) | 工况对齐的实操路径 |
|---|---|---|
| 模板调用逻辑 | 直接复用系统内置的默认托盘配置,对实际批次的物理衰减状态完全不做核对 | 依据实物抽检的测量数据,或者历史装柜作业的反馈记录,针对性地去开展货物限重参数的更新管理工作 |
| 限高阈值设定 | 仅仅把货物的物理累加高度填进去,叉车货叉的操作余量被直接忽略 | 必须把“顶层高度差”字段进行明确录入,为叉车货叉的抬升轨迹以及装卸口的净空环境预留出安全缓冲区间 |
| 加固占位处理 | 等到方案导出之后,再凭借个人经验去临时进行捆绑作业或者塞入填充材料 | 在配置阶段就提前填入加固占位空间的数值,让求解器在空间分配的过程中,直接把绑扎带以及护角的物理区域进行预留 |
| 数据校验时机 | 拿到结果直接拉到现场去开展试错作业,一旦出现干涉就开始盲目调整堆叠序列 | 在算法开展正式排布之前,就在详情页面对尺寸、限重以及间隙参数进行交叉验证,确保输入数据没有任何盲区 |
表格里的对比很直观。 但真正拉开差距的,是执行者是否愿意把校验动作前置。 很多团队宁愿花两小时在现场拆垛重装,也不愿意在后台花五分钟去修正那个决定性的间隙字段。这种倒置的优先级,才是高容积率方案频频触礁的底层逻辑。
四、 工具的能力边界与人工确认底线
工具从来不是万能的物理传感器。它只是把复杂工况转译成数学约束的桥梁。
求解器能够覆盖的区间。 Loadvis 的托盘管理模块,核心职能在于把非标准化的现场工况,映射为一套可供计算的参数体系。不管是借助 AI 快速录入,还是手动开展表单编辑配置工作,基准模板的搭建速度都可以得到极大程度上的提高。一旦参数输入完毕,求解器就会严格依照“限高—限重—间隙”这套规则链,去执行三维空间分配以及重心校核的运算工作。结果页输出的体积利用率以及载重分布比例,能够清晰反映方案的紧凑程度。3D 动画与装箱指导图,也可以用来直观地进行间隙占位合理性的视觉验证。
必须保留的人工核验底线。 数字模型永远无法自动感知现场环境的物理衰减与微观变量。操作人员必须亲自下场,去确认三件事: 其一,托盘的实际材质状态。新旧批次交替,或者受潮导致的承重折损率,这些动态指标必须被纳入考量。 其二,缠绕带、护角、防潮垫的实际物理厚度。图纸上的标注跟流水线上下来的实物,往往存在毫米级的公差。 其三,仓库装卸口的实际门框净空高度,以及叉车作业区域的地面平整度。 算法给出的,永远只是数学层面的最优解。 而现场真正需要的,是安全且可执行的落地解。 这两者之间,隔着一条必须靠人工经验去填平的鸿沟。任何试图完全绕过人工复核的自动化幻想,最终都会在装卸口前撞得粉碎。
五、 结语
装箱排布从来就不是一道纯粹的算术题。 它是物理约束在数字世界里的结构化投射。
把那些粗糙的工况变量,前置到托盘模板的配置阶段去进行结构化转译,远比在结果导出之后再去临时调整堆叠序列要稳妥得多。参数录入环节的严谨程度,会直接决定这套方案从屏幕平滑过渡到仓库地面的转化效率。 别指望算法能替你承担物理定律的惩罚。 保持录入数据与实物状态的同频共振。 执行层才不会在关键时刻掉链子。 参数准了。 车才能准时走。