체적 최적화의 함정: 데이터 입력의 질이 현장 적재 실패를 결정한다
컨테이너 문이 닫히지 않는다. 적재 시뮬레이션은 완벽하게 돌아갔다. 빈 공간 14%, 최적화된 패킹률, 이론상 하중 균형도 문제없어 보였다. 그런데 막상 현장 데크에 도착해 보면 팔레트가 기울고, 적재된 박스가 서로의 무게를 견디지 못해 측면이 찌그러진다. 문제의 발단을 로직으로 역추적해 보면? 알고리즘 버그가 아니다. 입력 단에서 잘려나간 물리적 제약 조건 때문이다. 우리는 종종 치수 데이터만 채우면 최적화가 끝난다 착각한다. 길이, 너비, 높이. 이 세 가지 숫자로는 하역 장비의 간섭, 국부 하중 분산, 컨테이너 벽면의 마찰 계수를 모델링할 수 없다.
과소평가되는 사각지대: 왜 치수만 믿는가
왜 이런 오류가 반복되는지 묻는다면, 데이터 입력 프로세스의 설계 철학부터 들여다봐야 한다. SKU 등록 작업은 대개 "속도"와 "배치 처리"에만 최적화되어 있다. CSV 한 방에 수백 개 레코드를 밀어 넣는 작업은 확실히 시원하다. 하지만 그 파이프라인에는 중량 중심(CoG), 허용 적층 하중, 취약 면에 대한 메타데이터가 누락되기 십상이다. 시스템은 빈 공간을 기하학적으로 채우는 데 탁월하지만, 물리 엔진이 아니다. 입력값이 평면적일수록 출력값은 현장과 괴리된다. 현장 지게차 운전사들이 왜 시뮬레이션 결과와 다르게 작업할 수밖에 없는지, 데이터 레지스트리를 열어보면 답이 나온다. 치수는 공간 점유율을 계산하지만, 하중은 구조적 무결성을 결정한다. 이 둘을 분리해서 생각하는 습관이 적재 실패의 근원이다.
파이프라인의 본질: 클릭이 아닌 매개변수 구조화
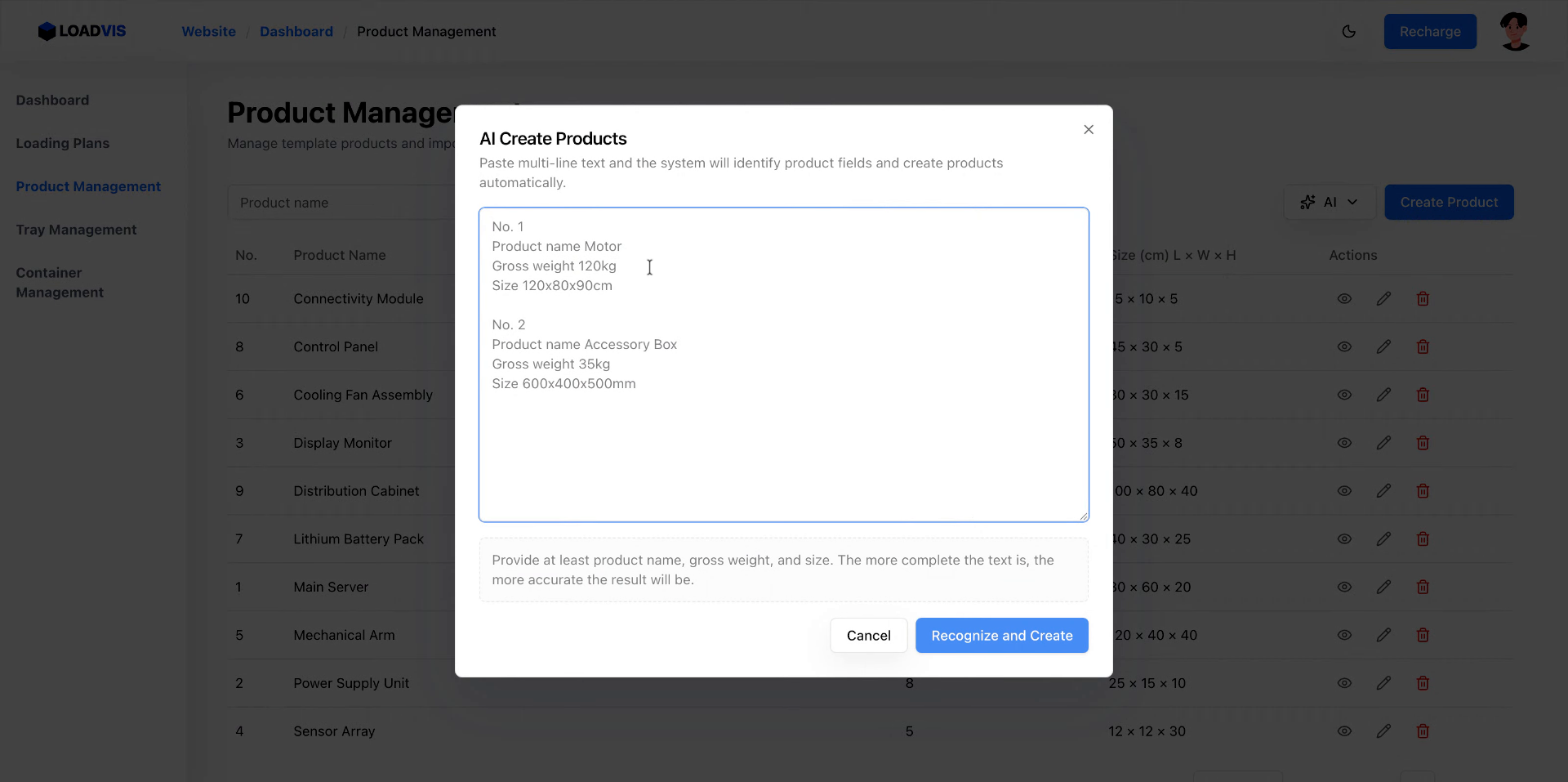
자연어 사양을 시스템에 밀어 넣는 파싱 루틴을 까보면, 작업의 핵심은 버튼 클릭이 아니라 데이터 구조화에 있다. 제품명, 총 중량, 가로×세로×높이 치수를 텍스트 블록으로 던진다. 빈 줄로 구분하면 일괄 처리가 트리거된다. 파싱 엔진이 자연어 토큰을 분해해 JSON 스키마에 매핑하고 DB에 적재하는 과정은 기계적으로 빠르다. 하지만 여기서 멈추면 안 된다. 인식 완료 후 바로 영구 저장을 실행하는 것은 도박과 다름없다. 추출된 값이 단위 변환에서 꼬였는지, 적재 시퀀스에서 상충하는 제약이 있는지 확인하는 게 본질이다.
접근 방식의 교차점: 잘못된 습관 vs 확실한 검증
현장에서 마주치는 두 가지 데이터 입력 패턴을 비교해 보자.
잘못된 접근 방식: 제조사 카탈로그의 표본 데이터를 그대로 긁어온다. 가로 1200 x 세로 1000 x 높이 1500, 중량 85kg. 입력 끝. 알고리즘이 알아서 적재 순서를 정해줄 거라 믿는다. 결과는? 최상단 적재 시 하중 분산 실패, 또는 컨테이너 문 앞에서의 균형 붕괴. 언제 오류가 발생하는가? 파싱이 단순히 문자열을 패턴 매칭해 숫자만 뽑아낸 순간이다. 시스템은 그 숫자를 절대값으로 해석하고, 적재 알고리즘은 경고 없이 통과시킨다. 현장에서는 팔레트가 휘고, 화물이 미끄러진다.
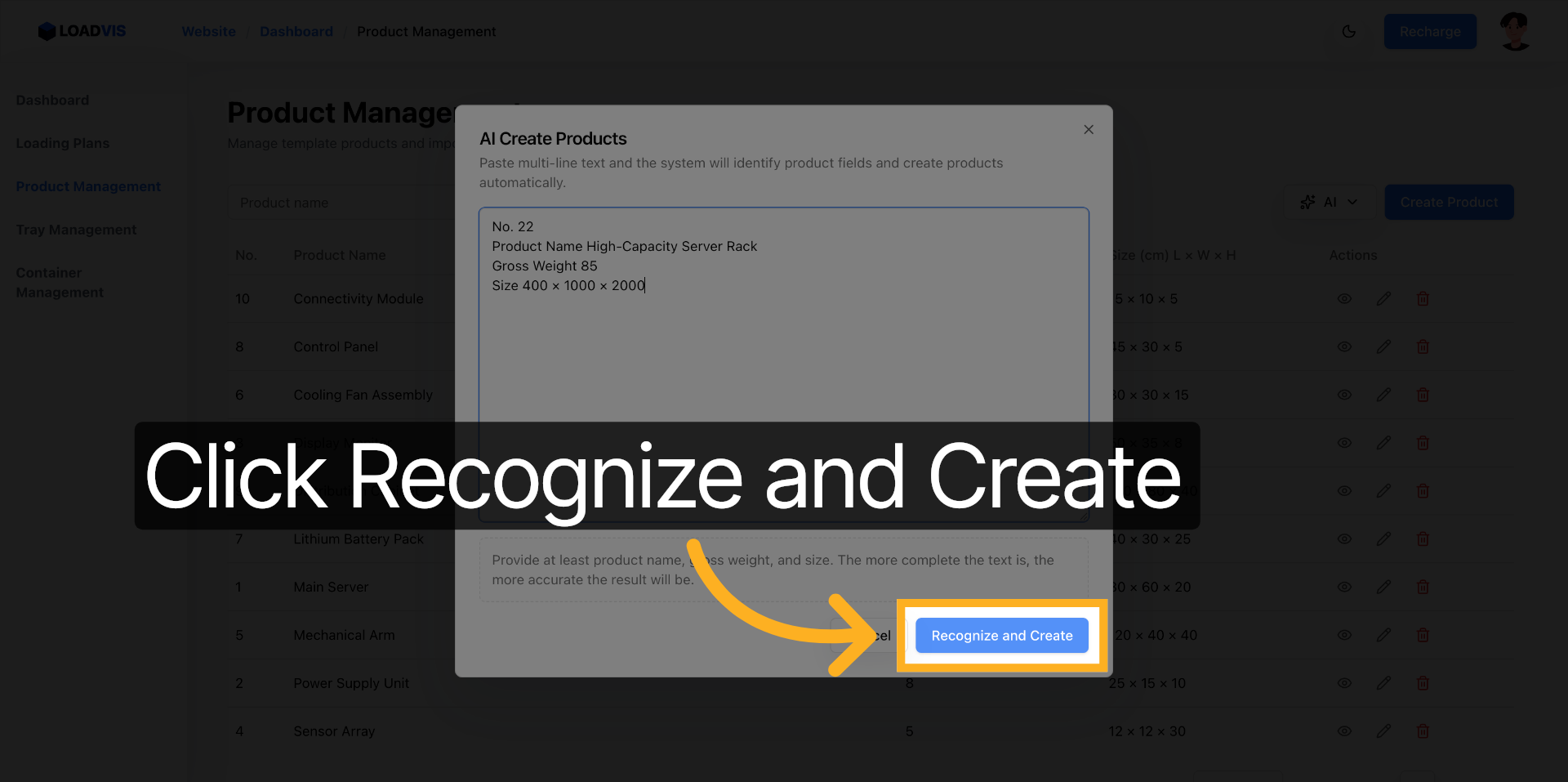
더 확실한 방법: 수동 보정을 전제하는 데이터 구조화다. 총 중량과 함께 최소 적재 용량과 최대 적재 용량을 명시한다. 팔레트 필요 여부(예/아니요)를 토글로 강제한다. 서버 랙이나 고밀도 부품처럼 국부 하중이 집중되는 SKU는 길이/너비/높이 필드 단위로 재측정 값을 입력한다. 어떻게 판단하는가? 중량 대비 치수 비율이 비현실적으로 뒤틀렸다면, 현장에서의 전복 확률을 먼저 계산해야 한다. 파싱이 끝난 레코드는 반드시 편집 모드로 열어 수치 간 논리적 모순을 훑어야 한다.
도구 지원 범위와 수동 검토의 필수 영역
AI 파싱 도구는 어디까지나 구문 분석기다. RESTful API를 통해 텍스트 토큰을 추출하고, 정규식을 우회해 구조화하는 데는 효율적이다. 하지만 물리적 제약을 추론하지는 않는다. 인식 및 생성이 완료되었다고 데이터 무결성이 보장되는 게 아니다. 다음 단계는 완전히 수동 검증 영역이다.
- 단위 일관성 검토:
cm와mm가 뒤섞여 있는지, 파운드/킬로그램 변환 오차가 누적되지 않았는지 크로스체크. - 적재 제약 충돌 확인: 최대 적재 용량이 1000kg인데, 하부 SKU의 허용 하중이 200kg이라면 알고리즘이 경고 없이 통과시킬 수 있다. 이 경계값을 사람이 직접 매핑해야 한다.
- 에지 케이스 샘플링: 전체 배치 중 10~15%를 무작위 추출해 실제 현장 적재 시나리오와 대조.
도구의 지원 범위는 입력 가속화와 초기 스키마 매핑에 그친다. 오류가 발생하는 시점은 대부분 저장 실행 이후, 적재 시뮬레이션이 실제 물리 엔진(또는 현장 규칙)과 충돌할 때다. 따라서 인식된 레코드는 제품 관리 목록에서 키워드 검색으로 호출해 재검토하는 절차를 반드시 거쳐야 한다. 퍼지 매치로 대상을 좁히고, 일치하는 레코드의 파라미터를 눈으로 훑는 과정이 생략되면, 자동화는 오히려 디버깅 시간을 늘리는 역효과를 낳는다.
데이터 레지스트리는 단순한 카탈로그가 아니다. 적재 알고리즘이 굴러가는 연료다. AI가 텍스트를 구조화해 주는 건 분명 시간 단축이다. 하지만 그 구조화된 덩어리에 현장의 무게 중심과 적층 한계를 어떻게 주입하느냐가 실제 적재 실패율을 가른다. 입력 필드의 빈칸을 채우는 속도를 경쟁할 게 아니라, 제약 조건의 경계를 어디에 긋는지 고민하는 편이 장기적으로 트럭 한 대, 컨테이너 한 칸의 비용을 아낀다. 검증 없는 자동화는 결국 현장에서의 수동 수정으로 되돌아온다.