Container-Konfiguration: Von theoretischer Volumenauslastung zur operativen Machbarkeit
Wir rechnen in Kubikmetern. Aber LKW-Rampen und Containerböden kennen keine perfekten Rechtecke. Es passiert ständig. Ein Beladeplan sieht auf dem Monitor zu 98% gefüllt aus, wirkt algorithmisch sauber, scheitert dann aber nach drei Paletten an der physischen Türhöhe. Warum? Weil wir in der täglichen Datenpflege oft vergessen, dass ein Stahlkasten kein abstrakter Würfel ist. Standardmaße gaukeln eine trügerische Einheitlichkeit vor, während sich die reale Welt aus verschleißbedingten Dellen, variabler Bodenbelastung und strengen Achslastgrenzen zusammensetzt. Sobald man diese Diskrepanz ignoriert, rutscht die Planung von der operativen Steuerung direkt in den Feuerwehr-Modus.
Parametrisierung wird häufig als reine Klickübung abgetan. Falsch. Jede definierte Regel – ob maximale Payload, Toleranz des Schwerpunkts oder explizite Türöffnungsgeometrie – wirkt als harter, unverrückbarer Filter auf den nachgelagerten Optimierungsalgorithmus. Fehlt dieser Input, produziert das System mathematisch korrekte, aber physisch unmögliche Beladesequenzen. Ich habe selbst erlebt, wie eine rein auf Volumendichte optimierte Stapelreihenfolge auf dem Terminal umgeworfen werden musste, weil die unterste Lage empfindlicher Kartons dem statischen Druck nicht standhielt. Das kostet Zeit. Und Geld. An dieser Stelle kommen manuelle Prüfungen, die nötig sind, ins Spiel; sie schließen die Lücke zwischen berechneter Idealwelt und der rauen Realität der Verlagerampe. Ohne diese Validierung bleibt jeder Plan eine akademische Übung.
Stammdaten als harter Filter gegen physische Kollisionen
Die Konfiguration beginnt nicht mit dem Füllen, sondern mit dem sauberen Definieren der Hülle. Im Arbeitsbereich geht es darum, exakte Innenmaße, reale Nutzlastgrenzen und spezifische Geometrieabweichungen zu hinterlegen. Der Workflow ist dabei bewusst zweigeteilt.
Zuerst wird der Basistyp angelegt. Sie öffnen die Containerverwaltung, wählen den Erstellungskontext und pflegen Werte wie den spezifischen Containercode oder eine Payload von 21500 kg. Die Eingabe von Innenlänge (589 cm), Breite (232 cm) und Höhe (233 cm) klingt banal, bildet aber das statische Gerüst für jede nachfolgende Berechnung.
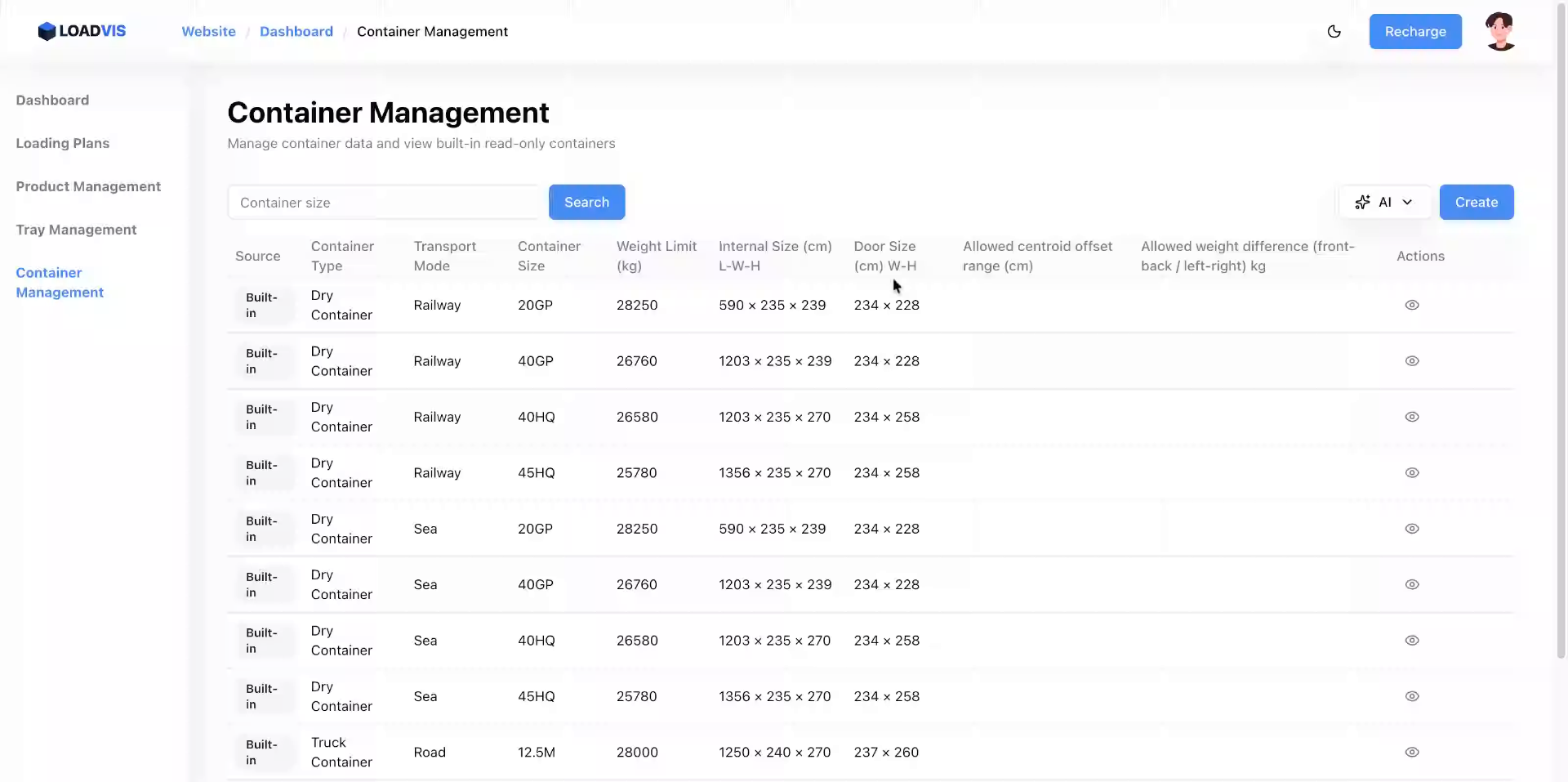
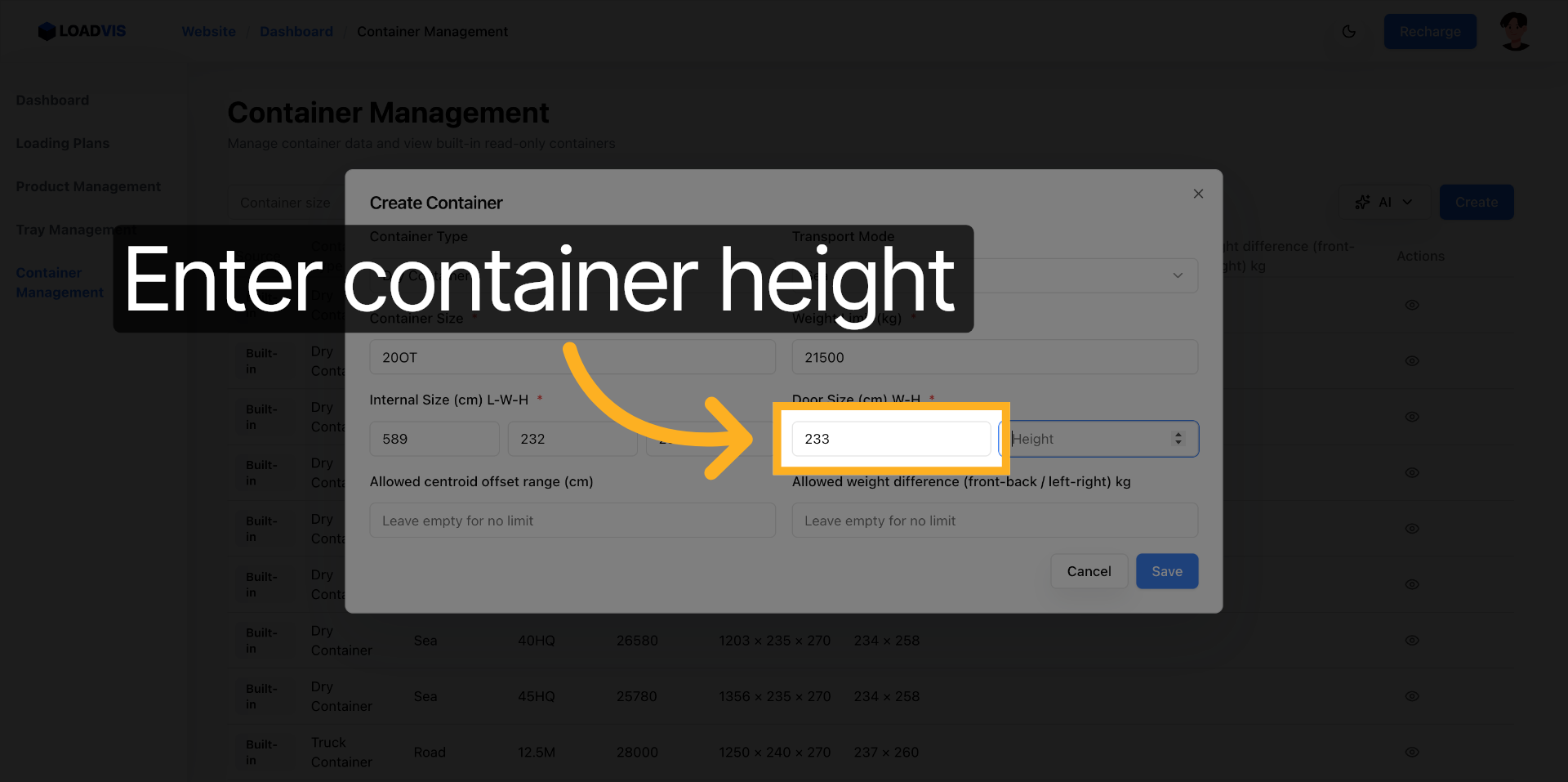
Wichtig: Die Türöffnung wird separat erfasst. Viele Systeme setzen Türhöhe gleich Containerhöhe. In der Praxis klaffen hier oft zehn bis fünfzehn Zentimeter auseinander. Wenn die Türöffnungshöhe hier pauschal mit den Innenmaßen gleichgesetzt wird, kollidiert der Gabelstapler im echten Einsatz. Manuelle Prüfungen, die nötig sind, umfassen immer das Abmessen der lokalen Flotte. Erst nach der Validierung aller Felder wird die Konfiguration persistiert.
Was passiert, wenn sich Rahmenbedingungen ändern? Nichts. Bis der LKW an der Rampe steht und das Tor nicht mehr aufgeht. Deshalb ist die Bearbeitung bestehender Datensätze kein nachträglicher Gedanke, sondern ein Kernbestandteil der Datenhygiene. Sie navigieren zur entsprechenden Zeile, aktivieren den Bearbeitungsmodus und passen die Payload von 21500 auf 21000 kg an, sobald die Transportgesellschaft die Obergrenze korrigiert. Gleichzeitig wird die Türöffnungshöhe auf realistischere 200 cm gedrosselt und die Türbreite analog angepasst.
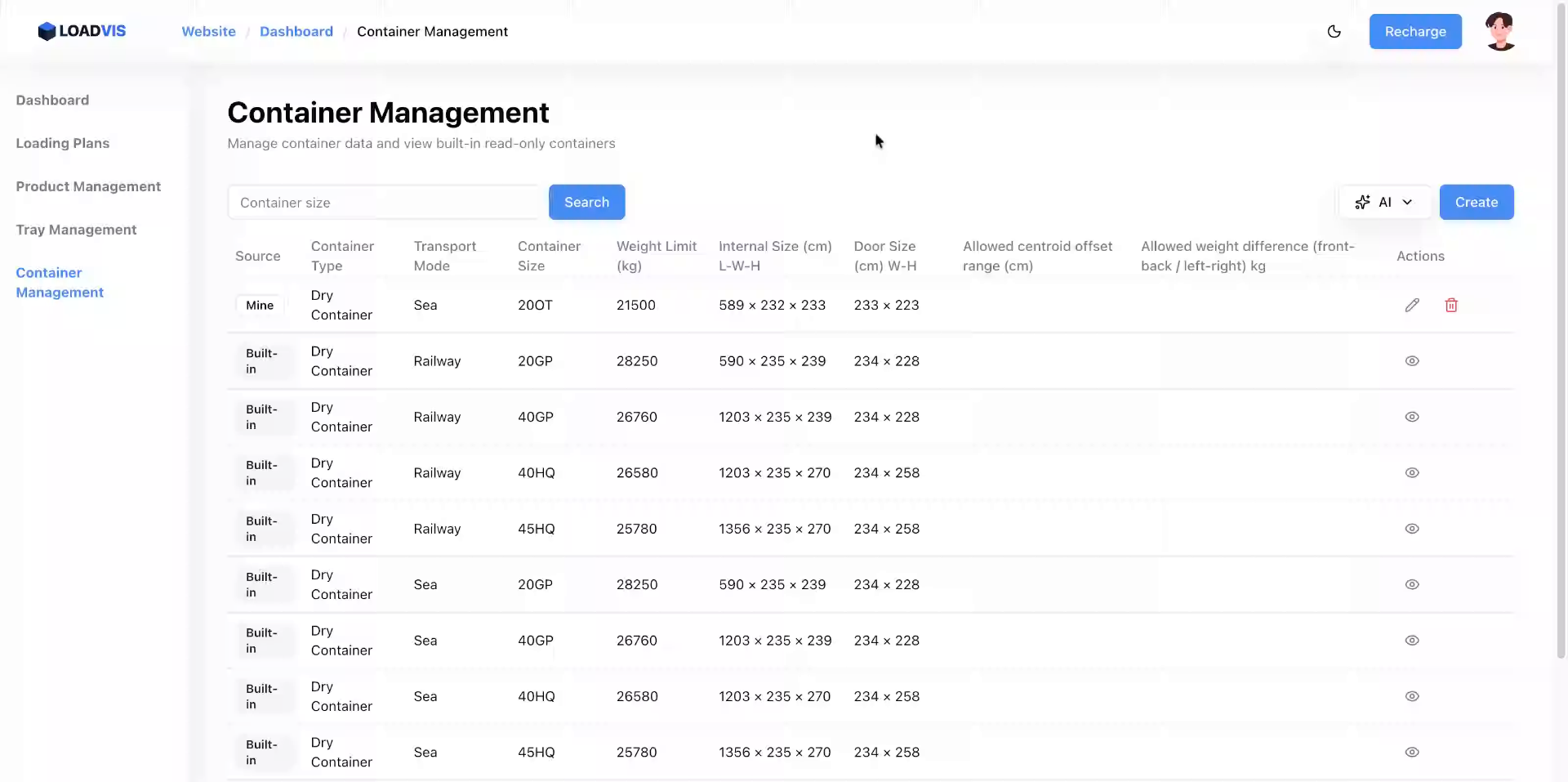
Diese granulare Anpassung verhindert, dass der Algorithmus in nachgelagerten Prozessen auf veraltete Annahmen zurückgreift. Speichert man die Änderungen nicht explizit, bleibt der Datensatz im alten Zustand. Ein klassischer Fehler, der oft erst beim Export des Ladeplans auffällt. Regelmäßige Audits der Stammdaten sparen hier mehr Zeit als jeder manuelle Korrekturlauf am Verladeort.
Wenn der Algorithmus die Realität verfehlt
Die Verwaltung wird schnell unübersichtlich, wenn Dutzende Spezifikationen parallel laufen. Filtermechanismen strukturieren die Liste. Statt manuell zu scrollen, queryen Sie nach spezifischen Größen wie „20GP", um sofort alle relevanten Datensätze zu isolieren. Das System gleicht die Treffer ab, zeigt die Ergebnisliste und liefert bei Klick die vollständigen Spezifikationen.
Wenn die Datenbasis jedoch veraltet ist, liefert auch die schärfste Suche nur alte Parameter. Moderne Implementierungen stützen sich zunehmend auf KI-gestützte Mustererkennung, um Stammdaten automatisch vorzuschlagen oder Anomalien zu flaggen. Aber Algorithmen lesen keine Ladebriefe. Sie erkennen nicht, ob eine bestimmte Holzpalette nach drei Wochen Feuchtigkeit aufgeweicht ist. Sie wissen nicht, ob der Zielhafen in Südamerika plötzlich 10% niedrigere Achslasttoleranzen durchsetzt.
Automatisierte Validierung gegen hinterlegte Constraints und die 3D-Simulation der Beladereihenfolge sind mächtige Werkzeuge. Sie decken Volumengewichtskonflikte früh auf. Sie generieren Leitdokumente. Die finale Freigabe liegt aber weiterhin beim Verladepersonal. Manuelle Prüfungen, die nötig sind, betreffen die tatsächliche Bodenbelastungsgrenze bei Punktlasten, die individuelle Steifigkeit von Verpackungen und lokale Compliance-Vorschriften. Das System liefert die planerische Entscheidungsgrundlage. Es ersetzt keine physische Inspektion.
Operative Machbarkeit entsteht nicht durch höhere Füllgrade. Sie entsteht durch ehrliche Constraints. Wer die physischen Grenzen – von der Türhöhe über die Schwerpunkttoleranz bis zur realen Verpackungssteifigkeit – als harte Filter definiert, vermeidet Stillstände. Der Unterschied liegt im Detail. Und in der Bereitschaft, Daten nicht nur zu pflegen, sondern sie kontinuierlich gegen die Realität zu validieren.