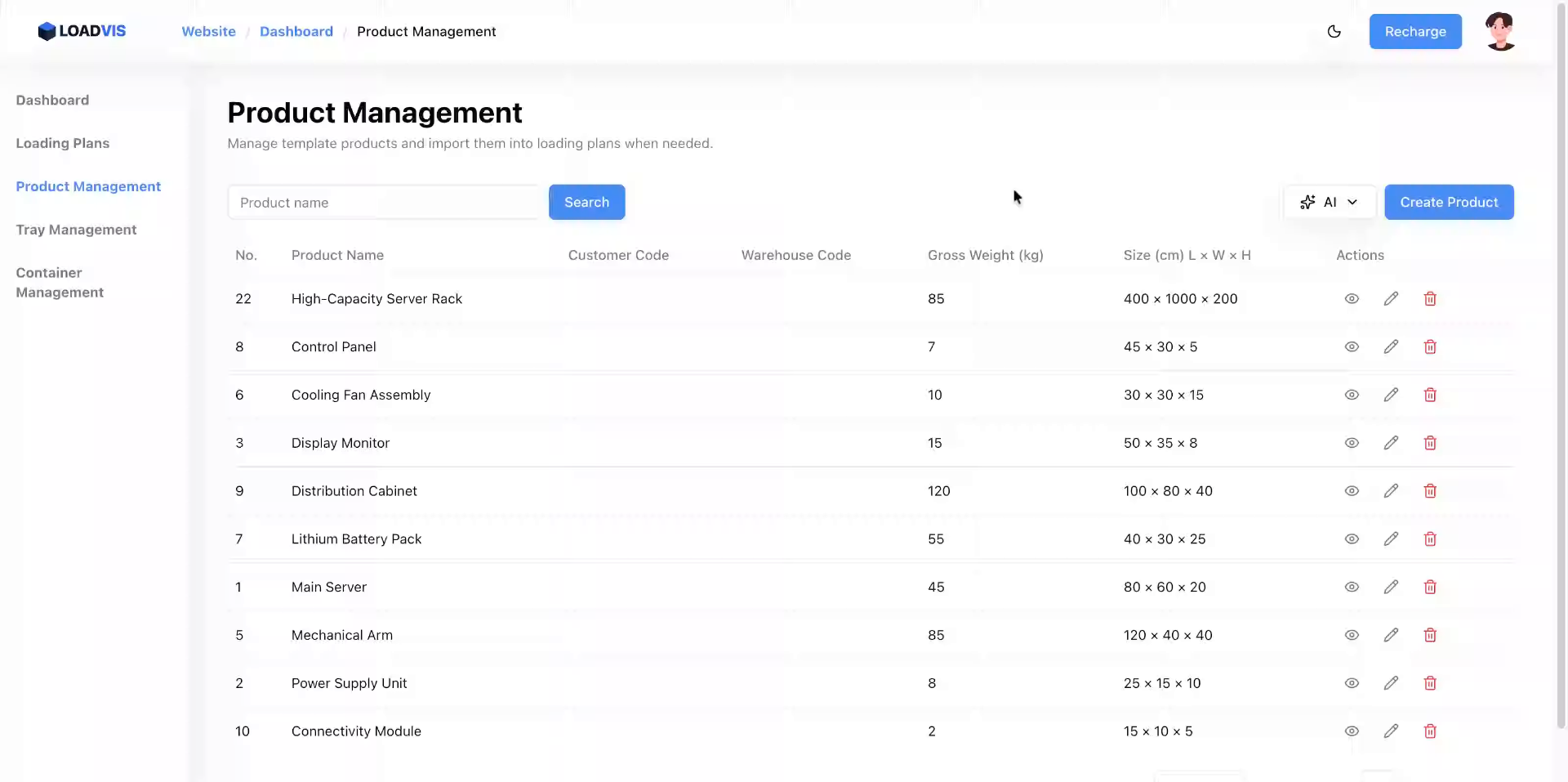
Revisione Operativa: Gestione Anagrafica Prodotti e Validazione Dati
Il collo di bottiglia non è mai il click. È la fedeltà del dato al momento della bolla di carico. Cinquanta referenze arrivano sparse. Formattazione eterogenea. Unità di misura che saltano da libbre a kg senza preavviso. Il parser le ingoia. Il sistema le normalizza. Se accetti l'output a occhi chiusi, il gate ti rispedisce indietro. Sempre. La registrazione manuale regge fino a un certo volume, poi collassa sotto il peso della ridondanza operativa. Qui entra in gioco l'estrazione automatica. Ma attenzione: non è magia. È un filtro statistico. E come ogni filtro, lascia passare il rumore se non lo calibri.
Il motore non inventa. Estrae token. Cerca pattern. Tenta un mapping forzato verso peso lordo, ingombri e vincoli di palletizzazione. Quando il testo sorgente è un PDF scansionato male o una scheda tecnica zeppa di clausole legali, il drift è inevitabile. Il sistema genera una bozza. La scrive nel database. Fino a qui, tutto lineare. Ma la validazione richiede una frizione umana. Incrocia le specifiche originali. Sempre. Un errore di dieci chilogrammi su un'unità di carico non è un typo. È un vettore di instabilità nel calcolo dello stivaggio.
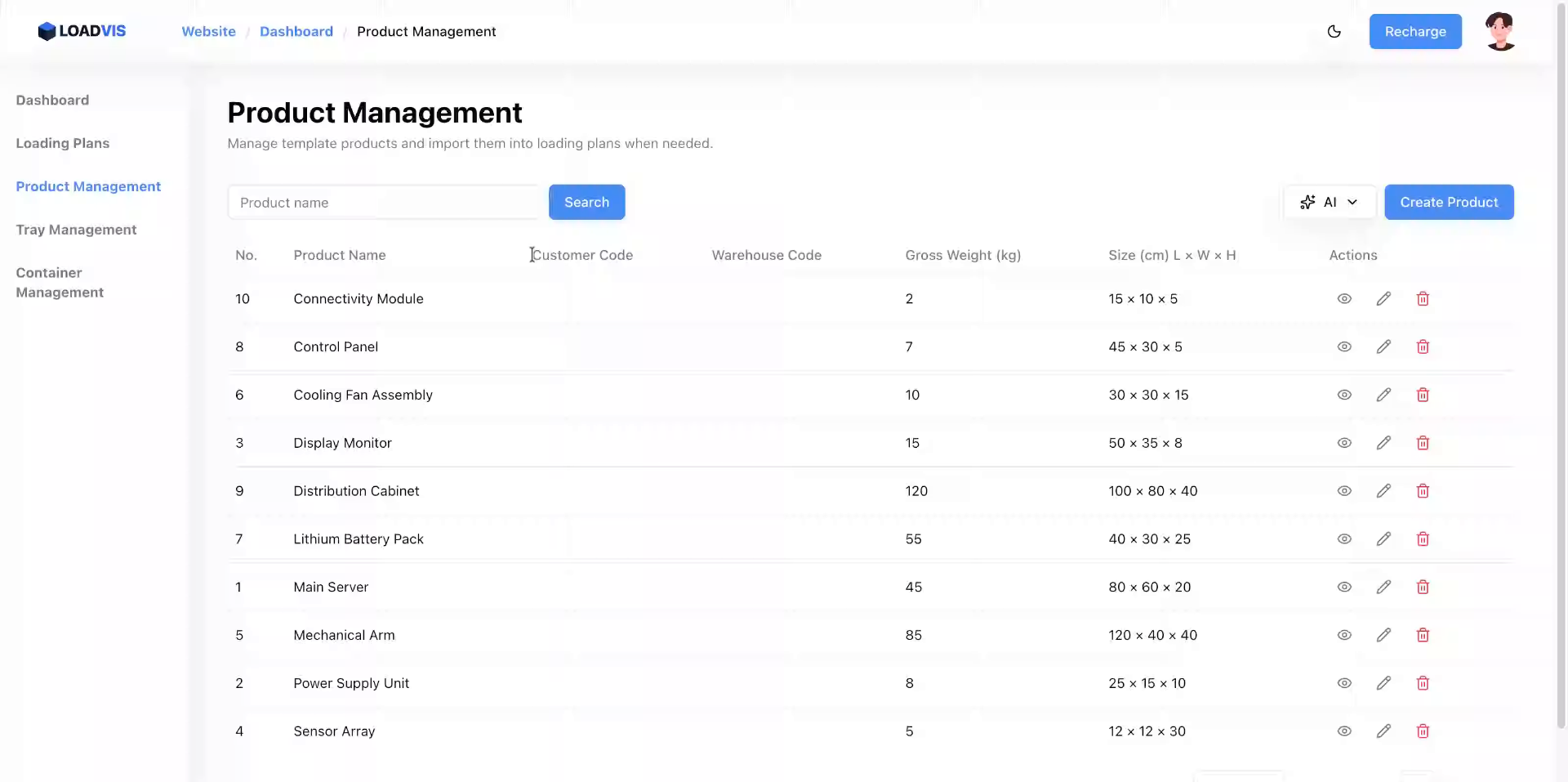
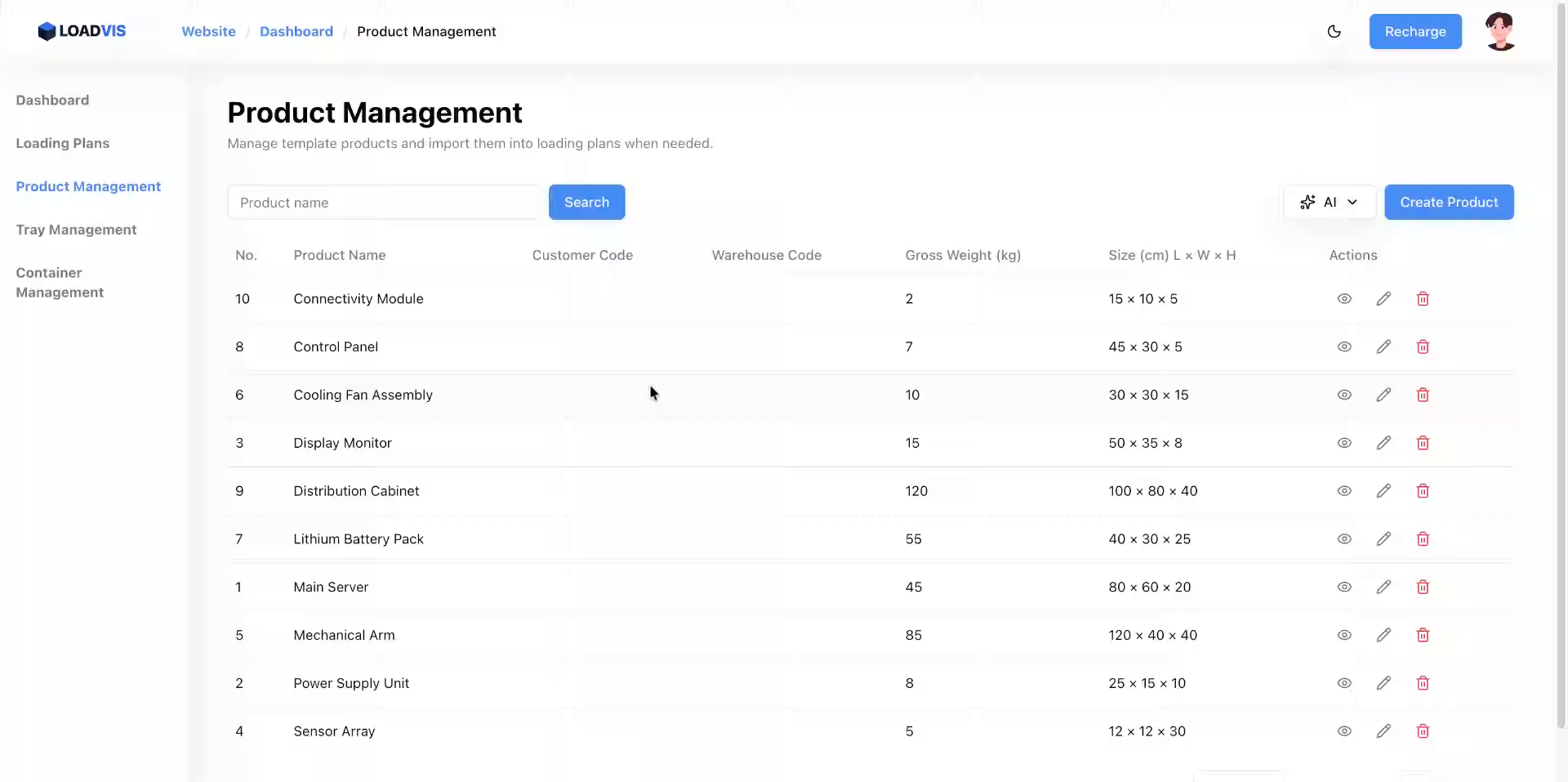
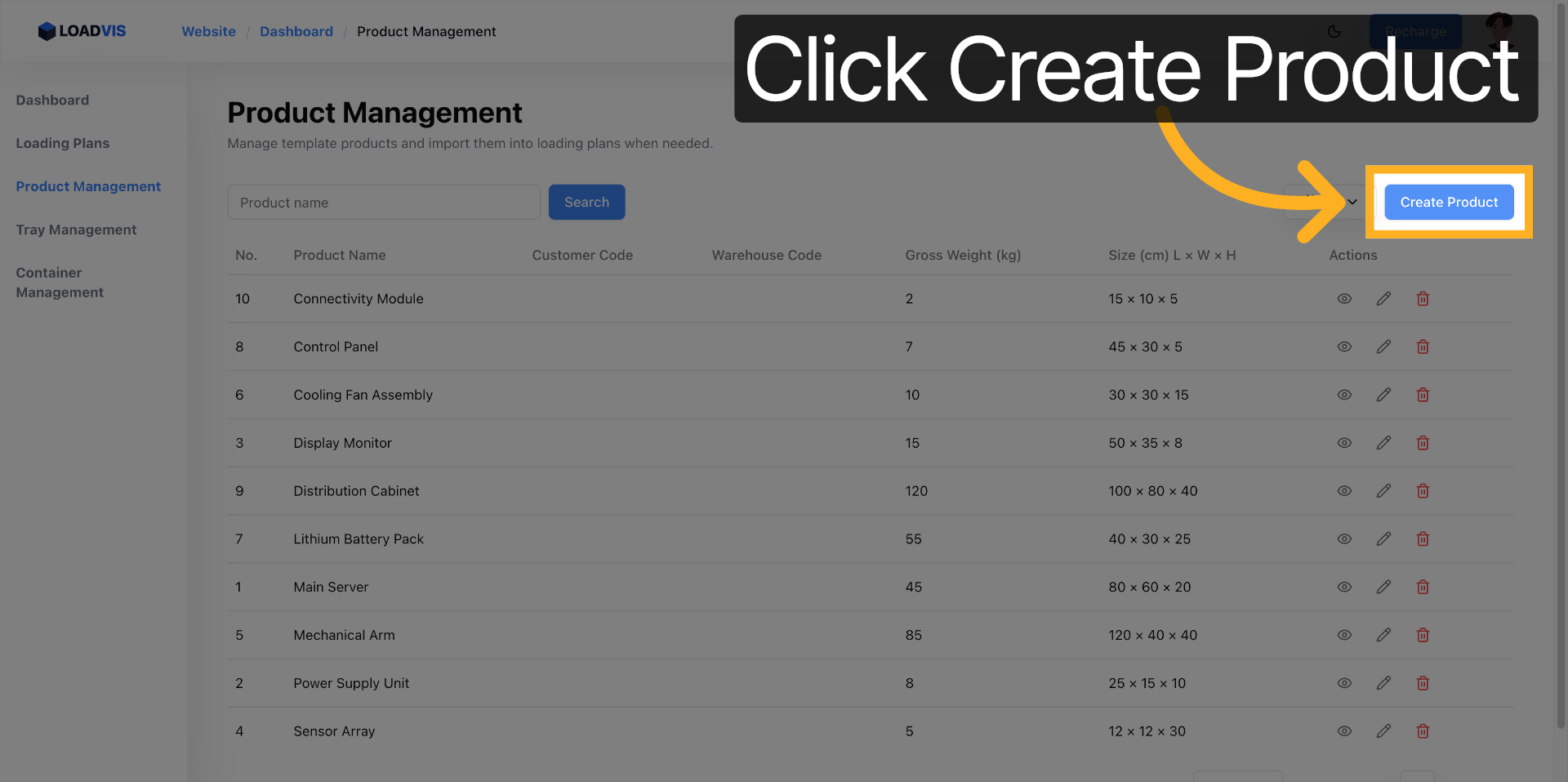
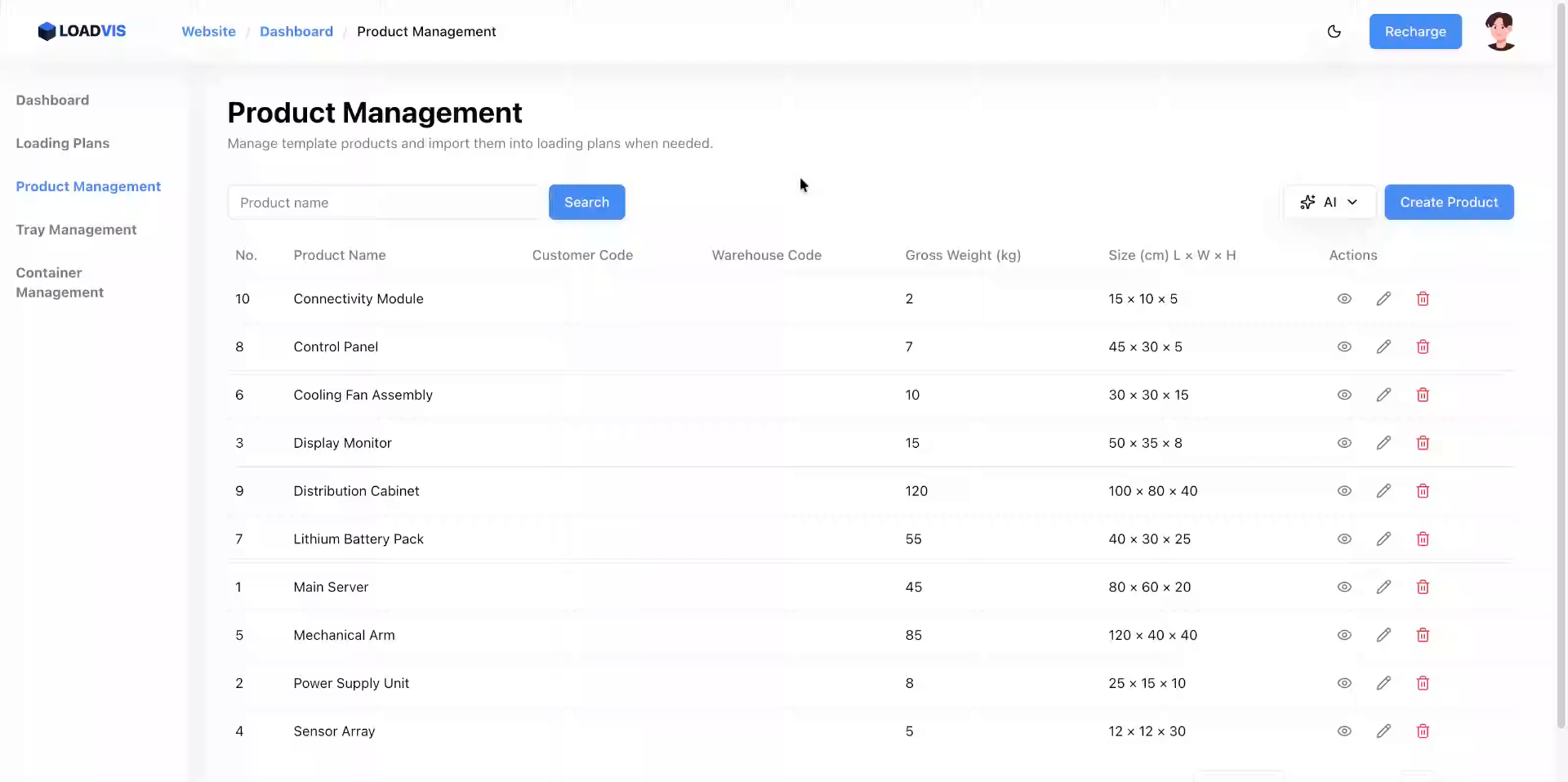
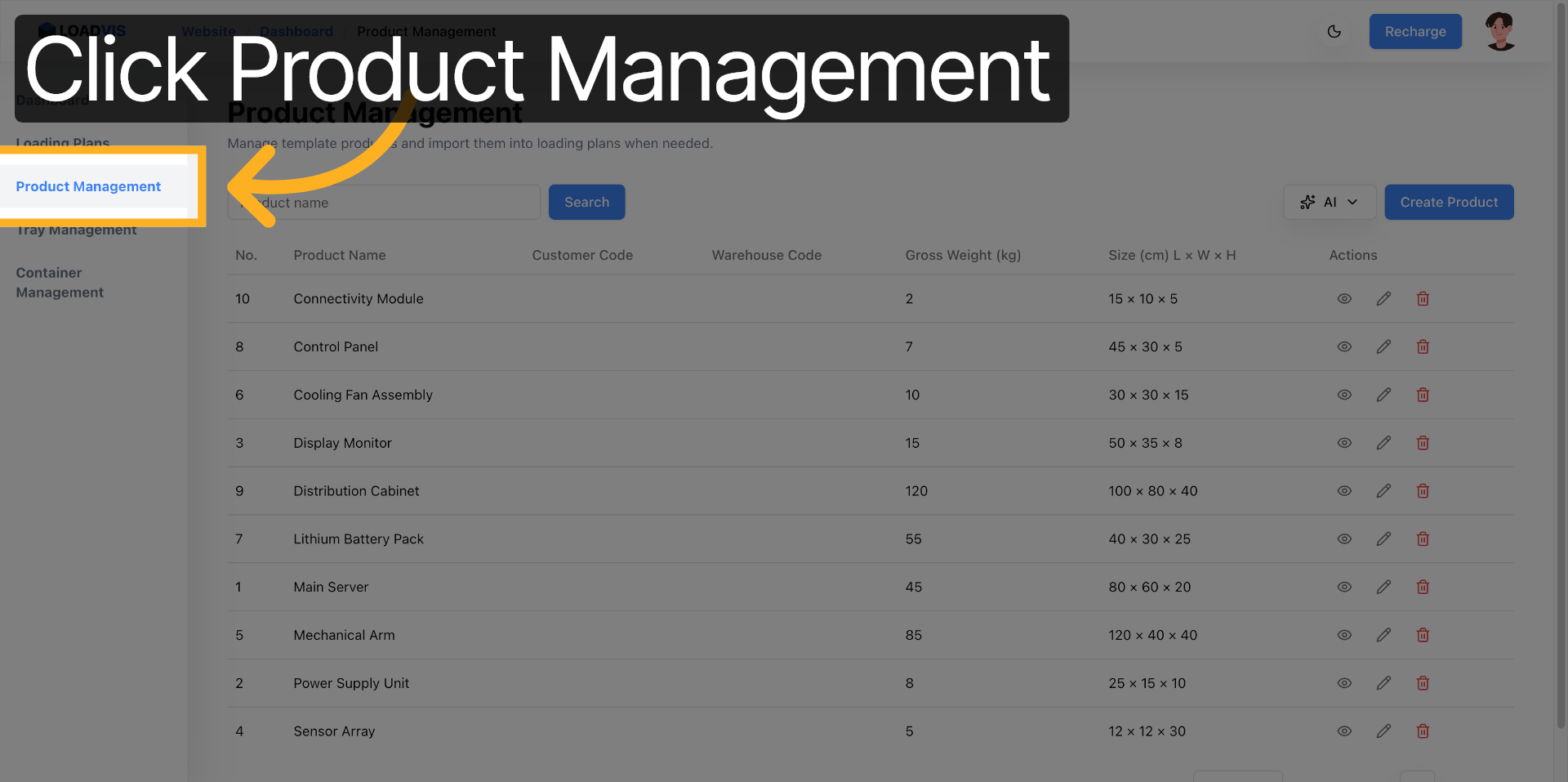
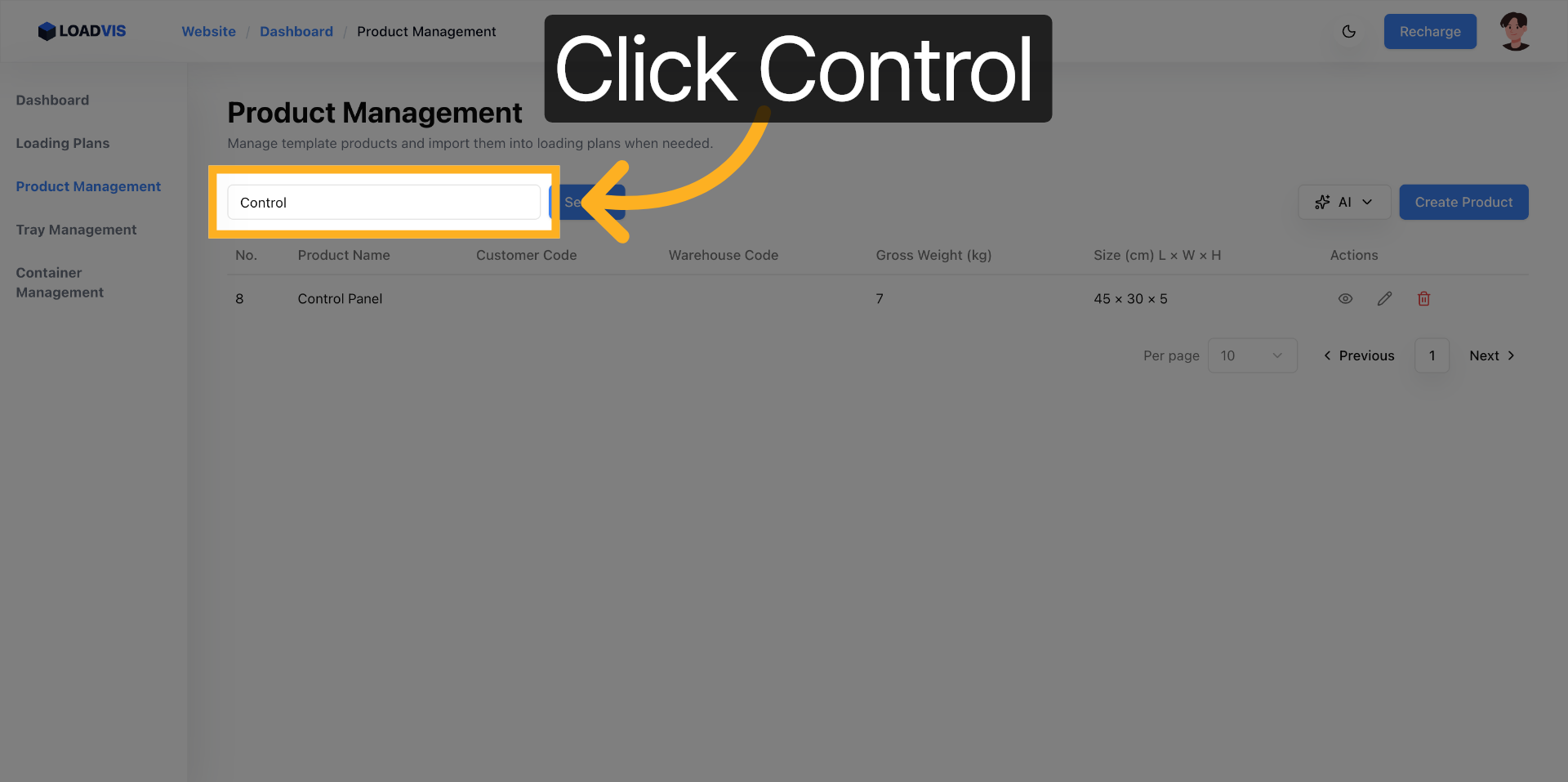
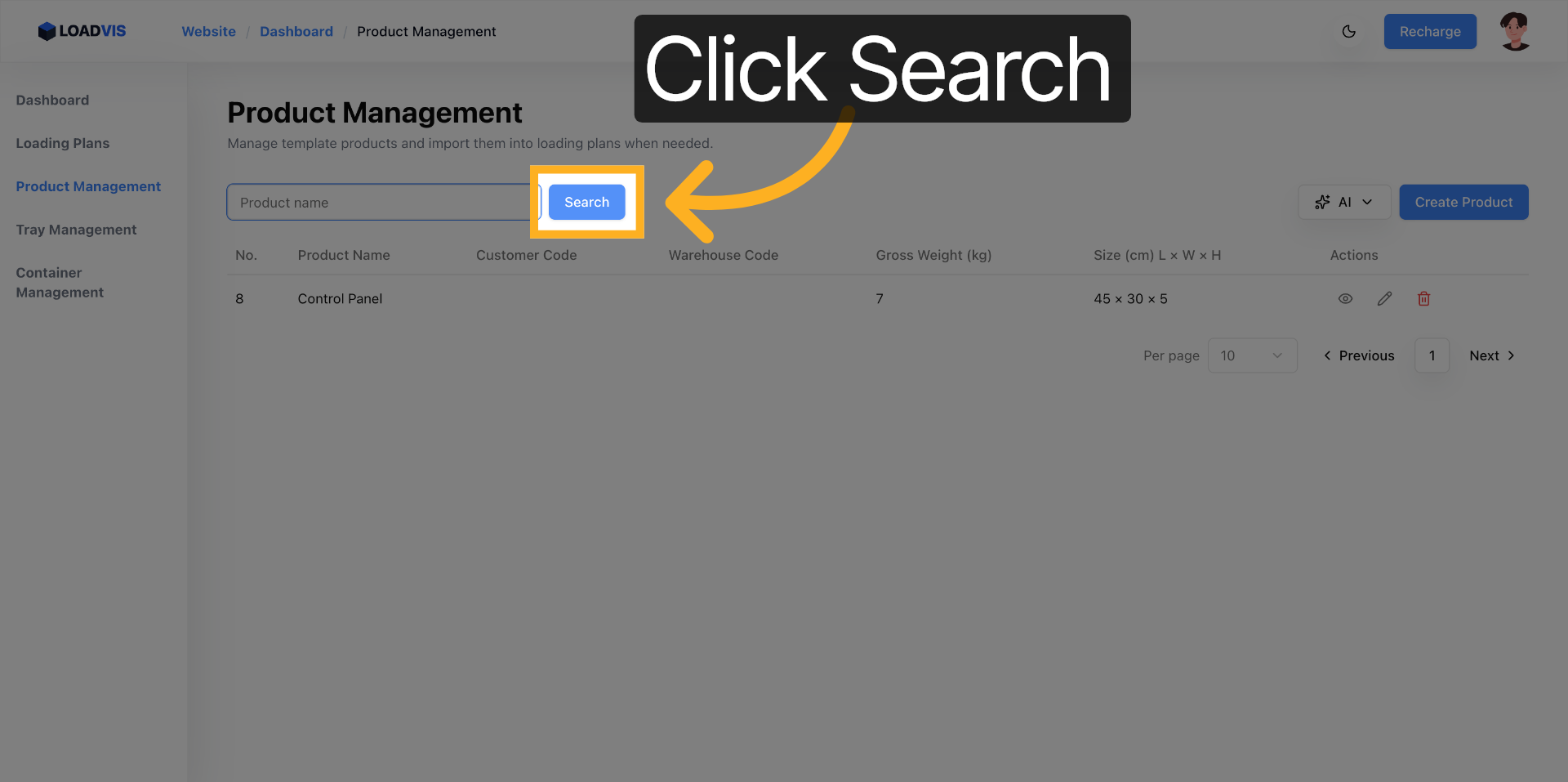
Accedi all'area di configurazione. Gestione Prodotti non è un semplice CRUD. È il punto di controllo dove le dimensioni fisiche diventano vincoli matematici. Avvia l'inserimento batch. Incolla il testo grezzo. Separa le referenze con righe vuote. Il parser segmenta. Pulisce. Normalizza.
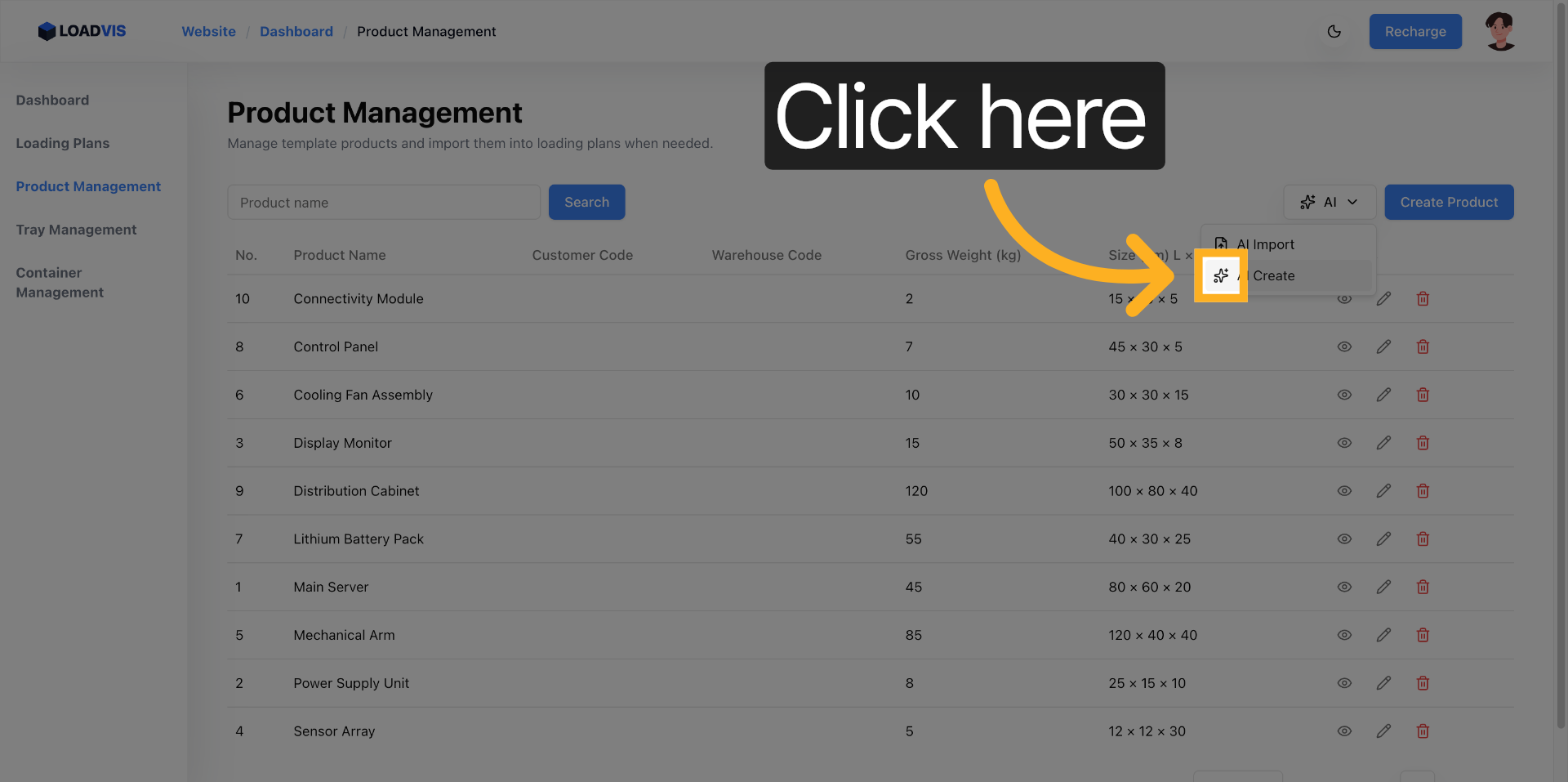
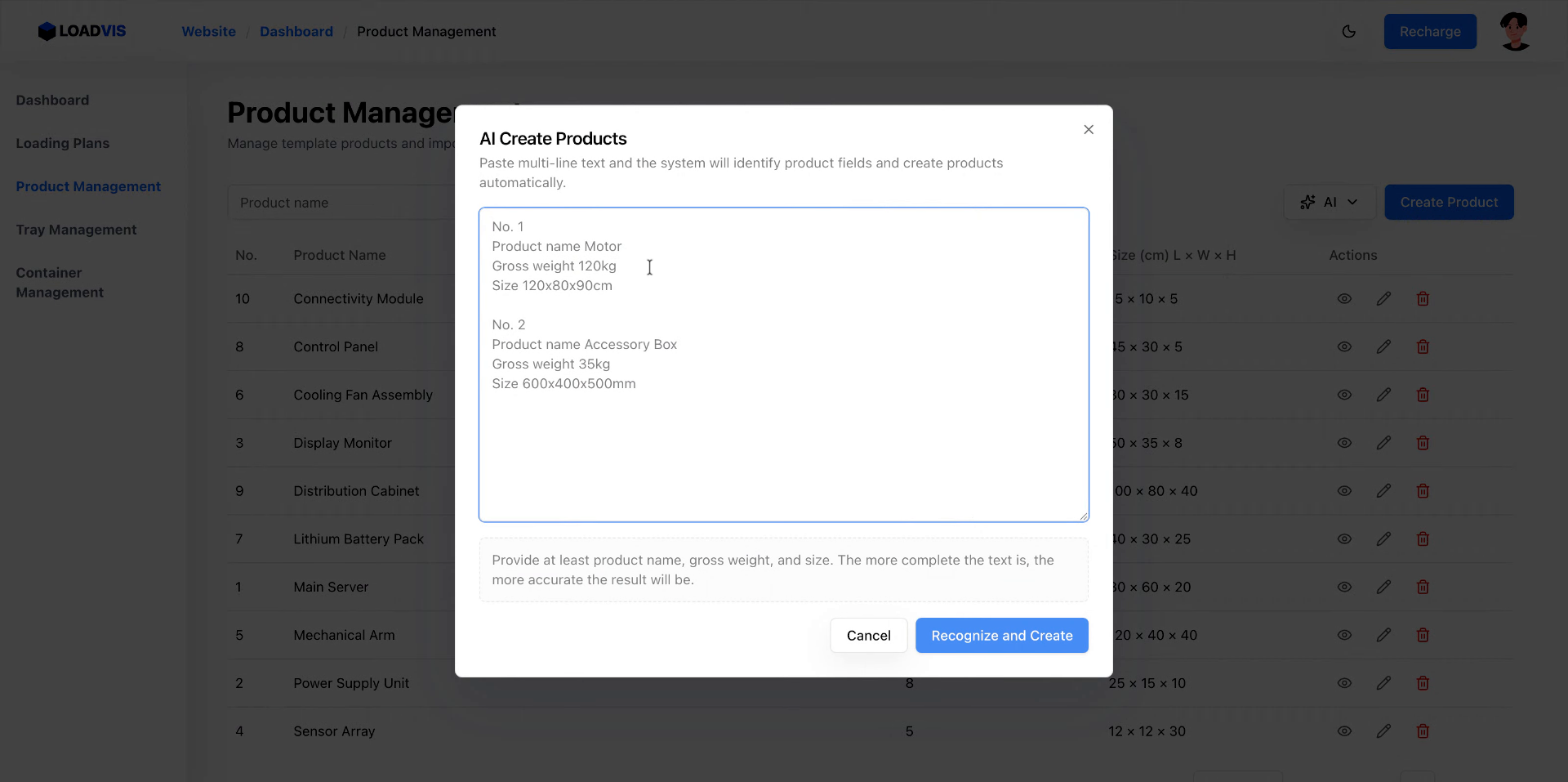
Premi il trigger di riconoscimento. La pipeline scrive i record. Non fermarti. I modelli linguistici falliscono sui limiti di impilamento. O confondono peso netto con peso lordo. O ignorano l'opzione pallet. Ecco perché il commit finale deve passare attraverso un controllo puntuale. Vai nel record. Verifica le unità di misura. Controlla la capacità di carico minima e massima. Se il sistema propone un valore, non è una verità assoluta. È un'ipotesi probabile. La fisica del magazzino non negozia.
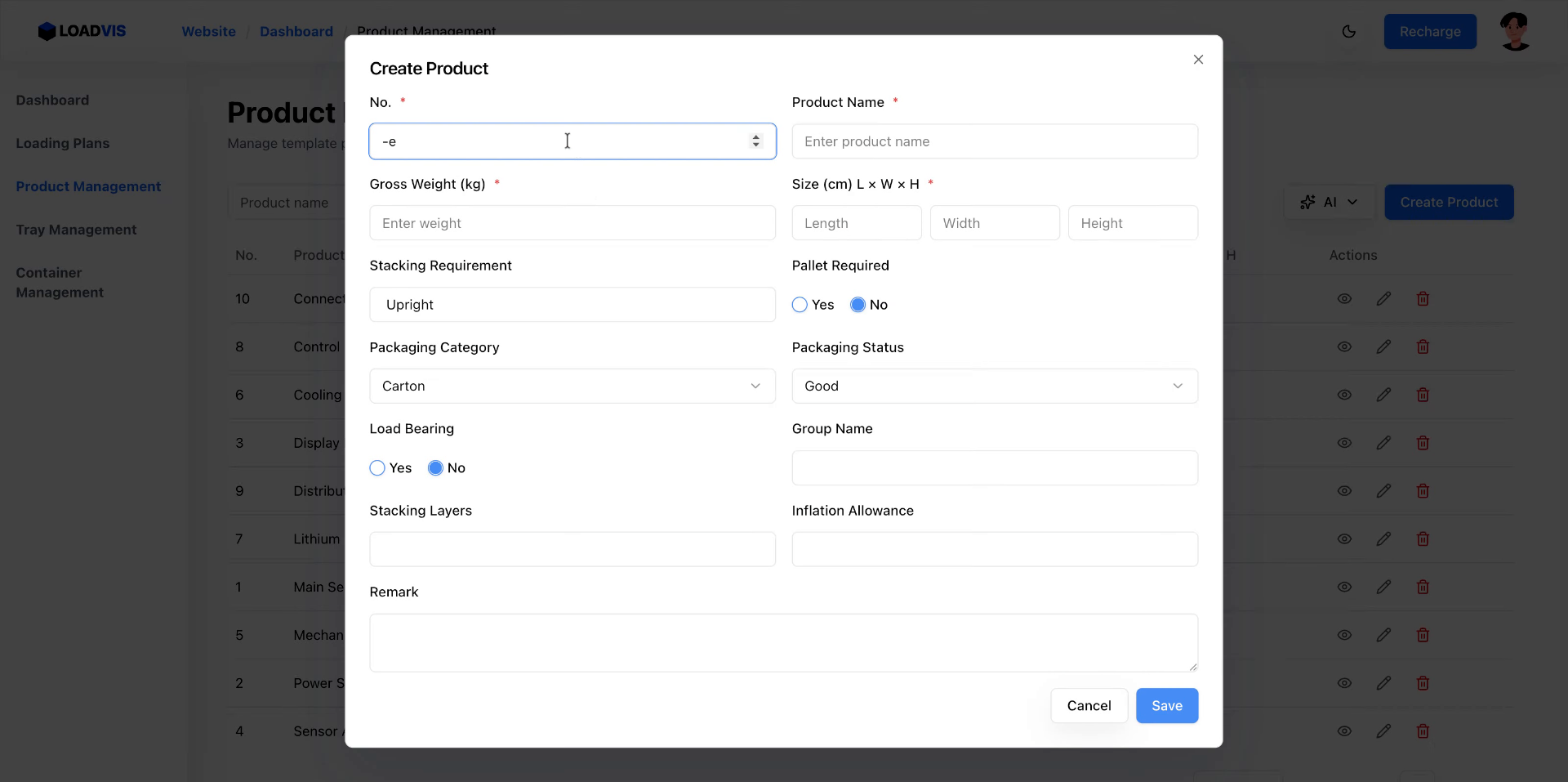
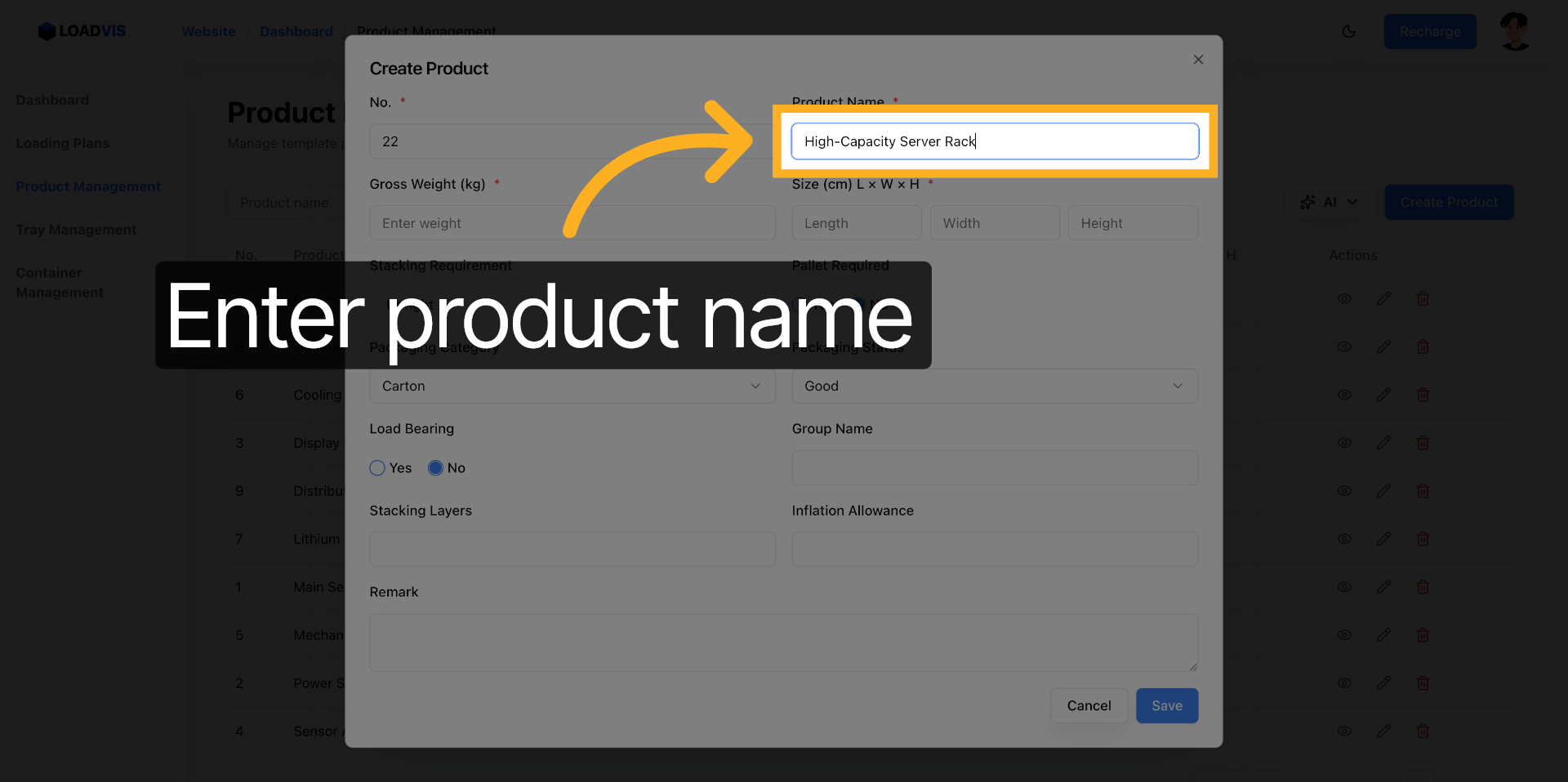
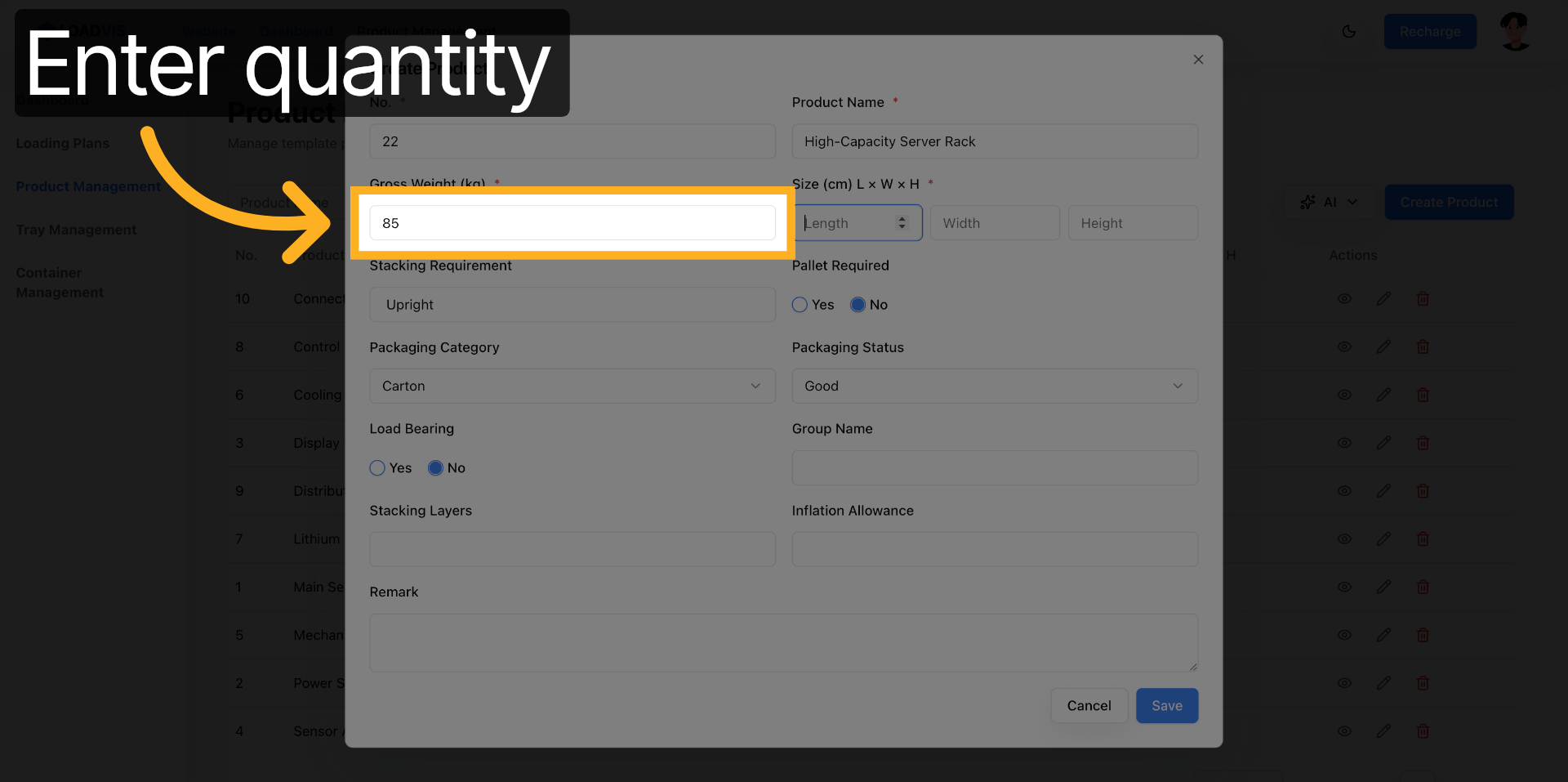
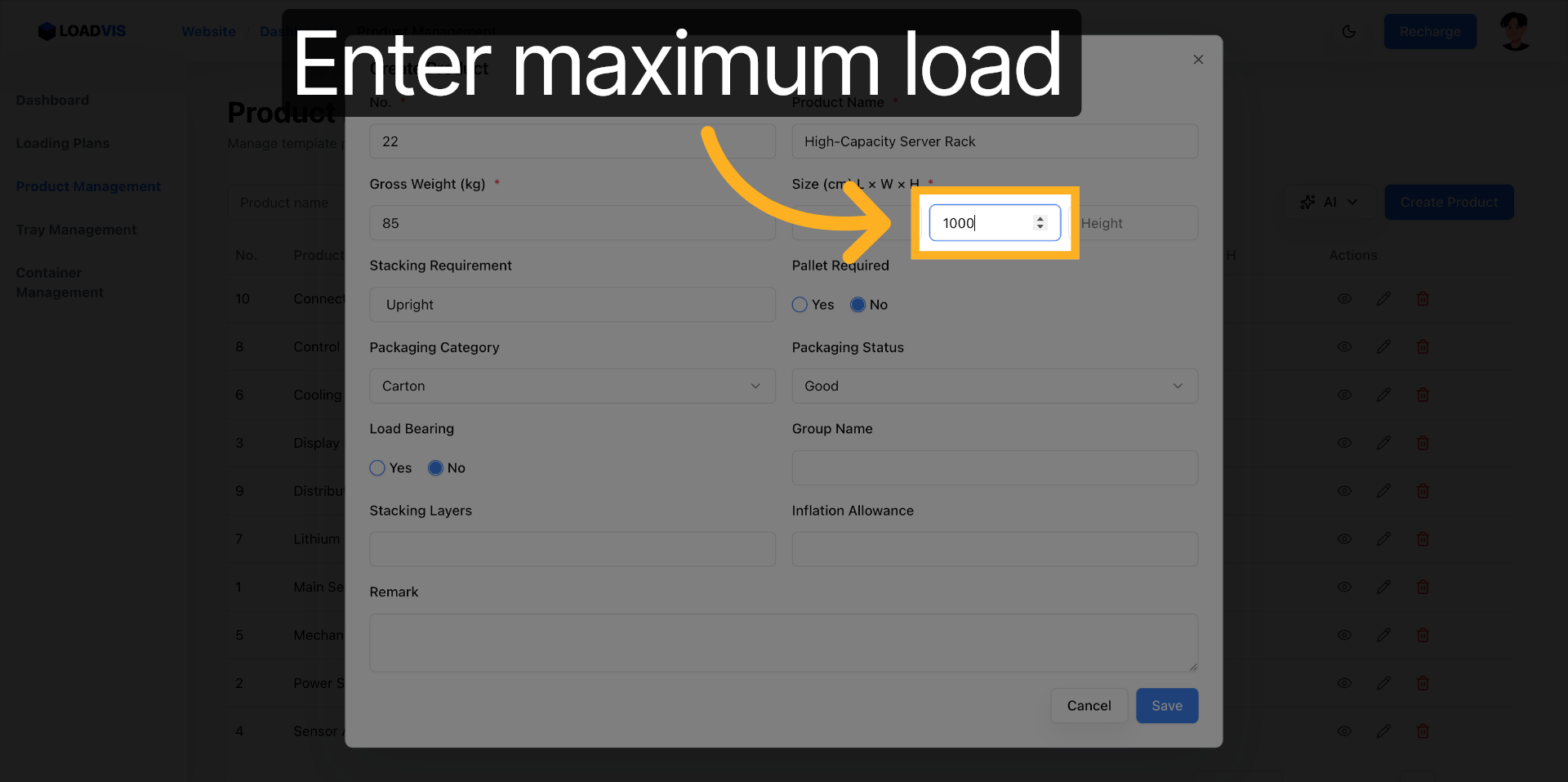
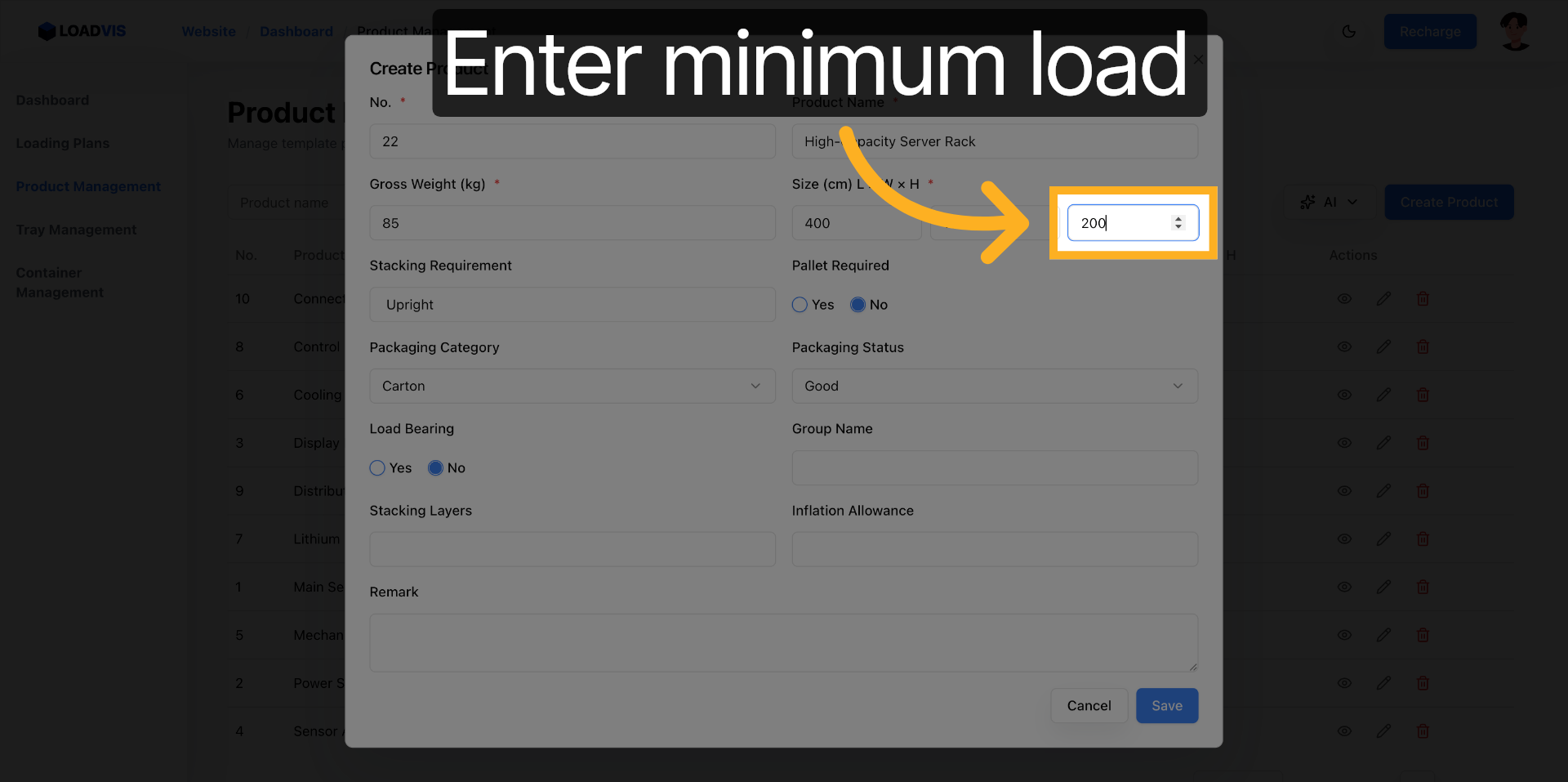
La creazione manuale resta l'ancora di salvataggio. Campo per campo. Serie, ingombri L×P×A, soglie di carico. Compila. Salva. La validazione lato server rifiuterà l'input se mancano i vincoli strutturali. È voluto. Meglio un errore a schermo che un container che si ribalta in banchina.
Se stai orchestrando questo flusso da un backend Django, il pattern è chiaro: l'API RESTful riceve la richiesta di creazione, valida lo schema JSON, e scrive su storage. Non bypassare la sanitizzazione. Se i file di origine finiscono su S3, il webhook di elaborazione deve restituire un payload pulito prima di tentare la scrittura anagrafica. L'idempotenza qui è fondamentale. Il retry su endpoint di importazione batch genera duplicati silenziosi. Pulisci prima di commitare. La latenza del network non giustifica la corruzione referenziale.
I fornitori aggiornano le schede. I parametri slittano. Apri il record esistente. Modifica il peso lordo. Correggi le dimensioni. Abilita il vincolo pallet se il carico lo richiede.
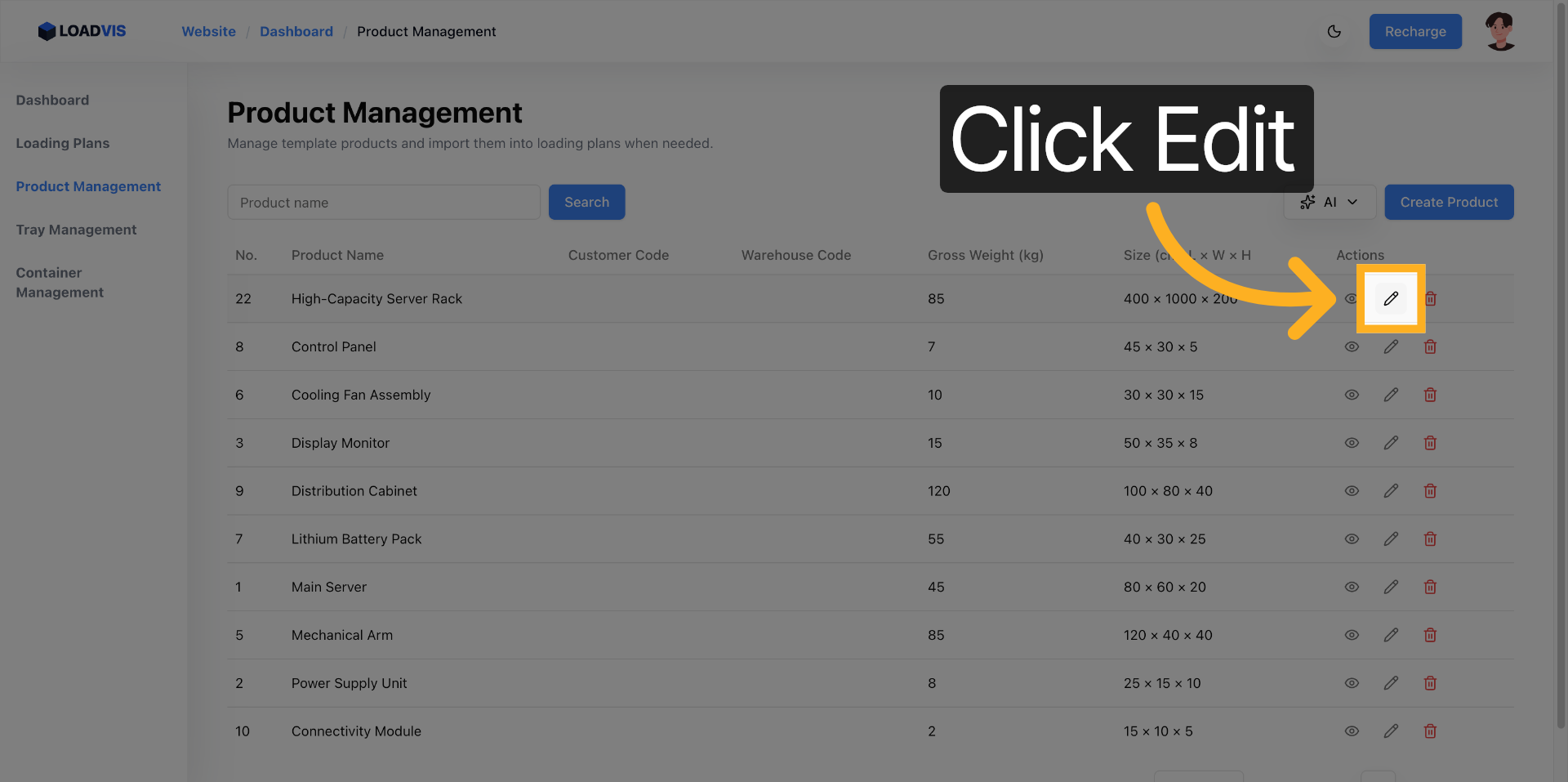
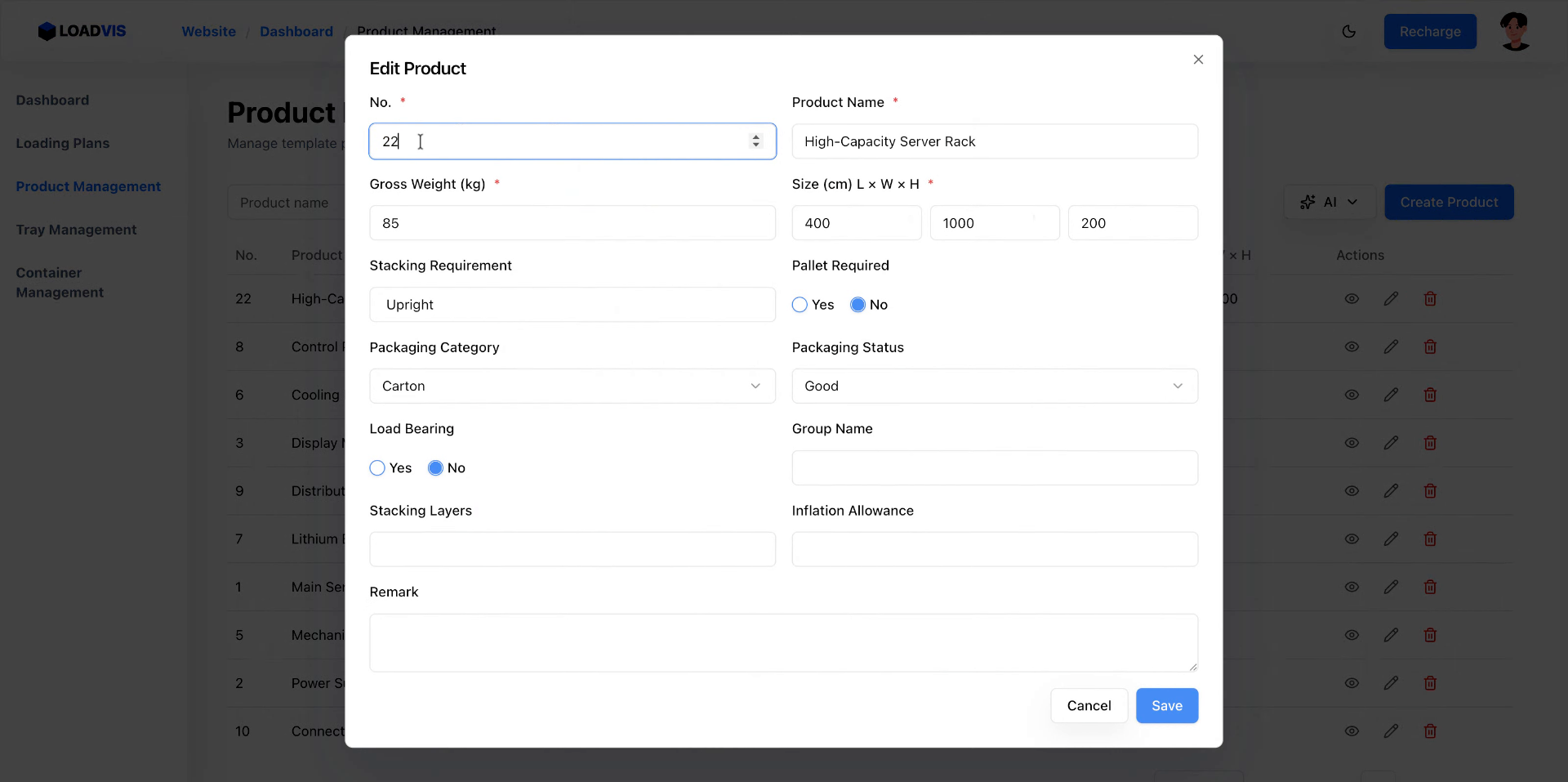
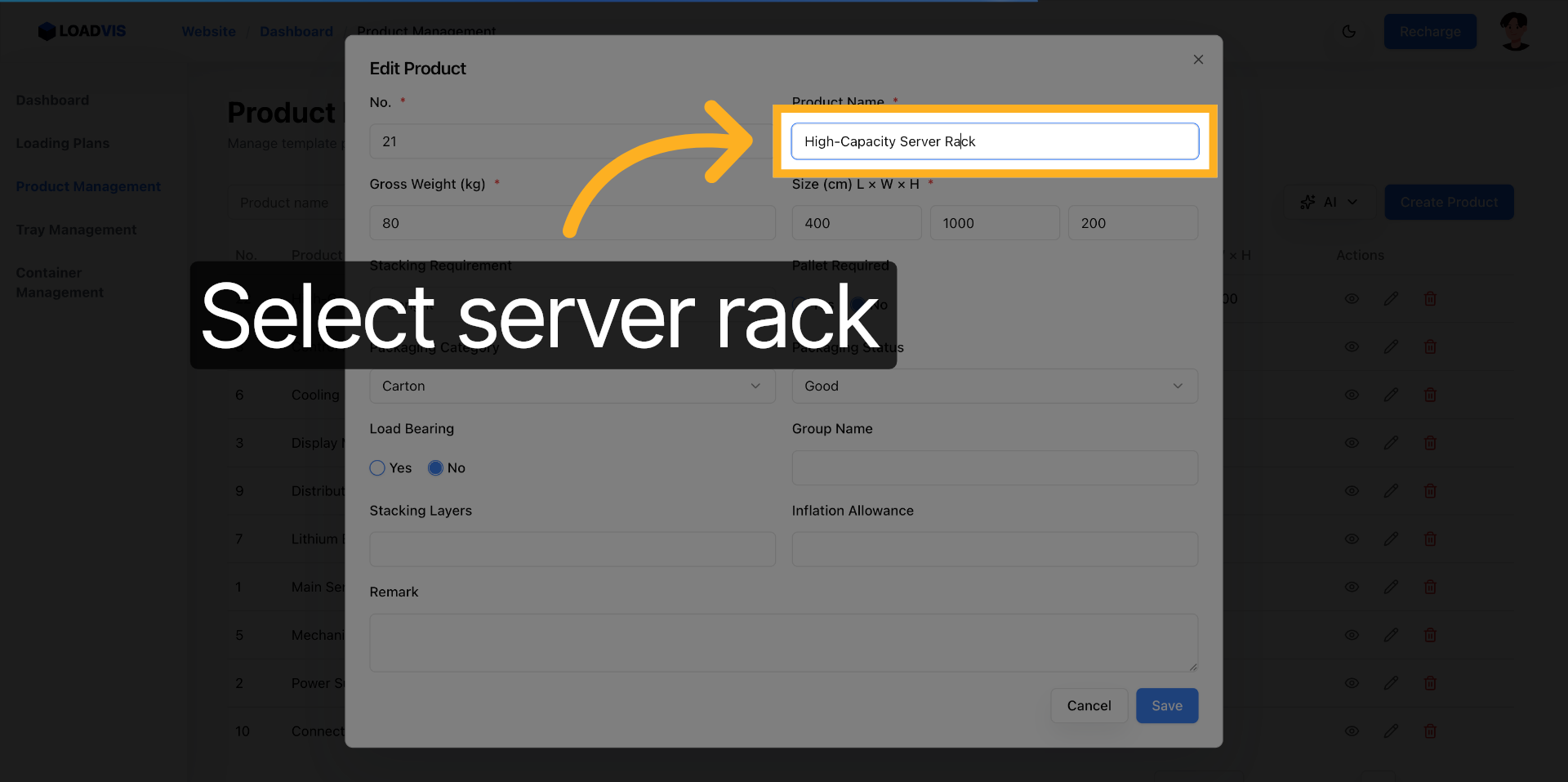
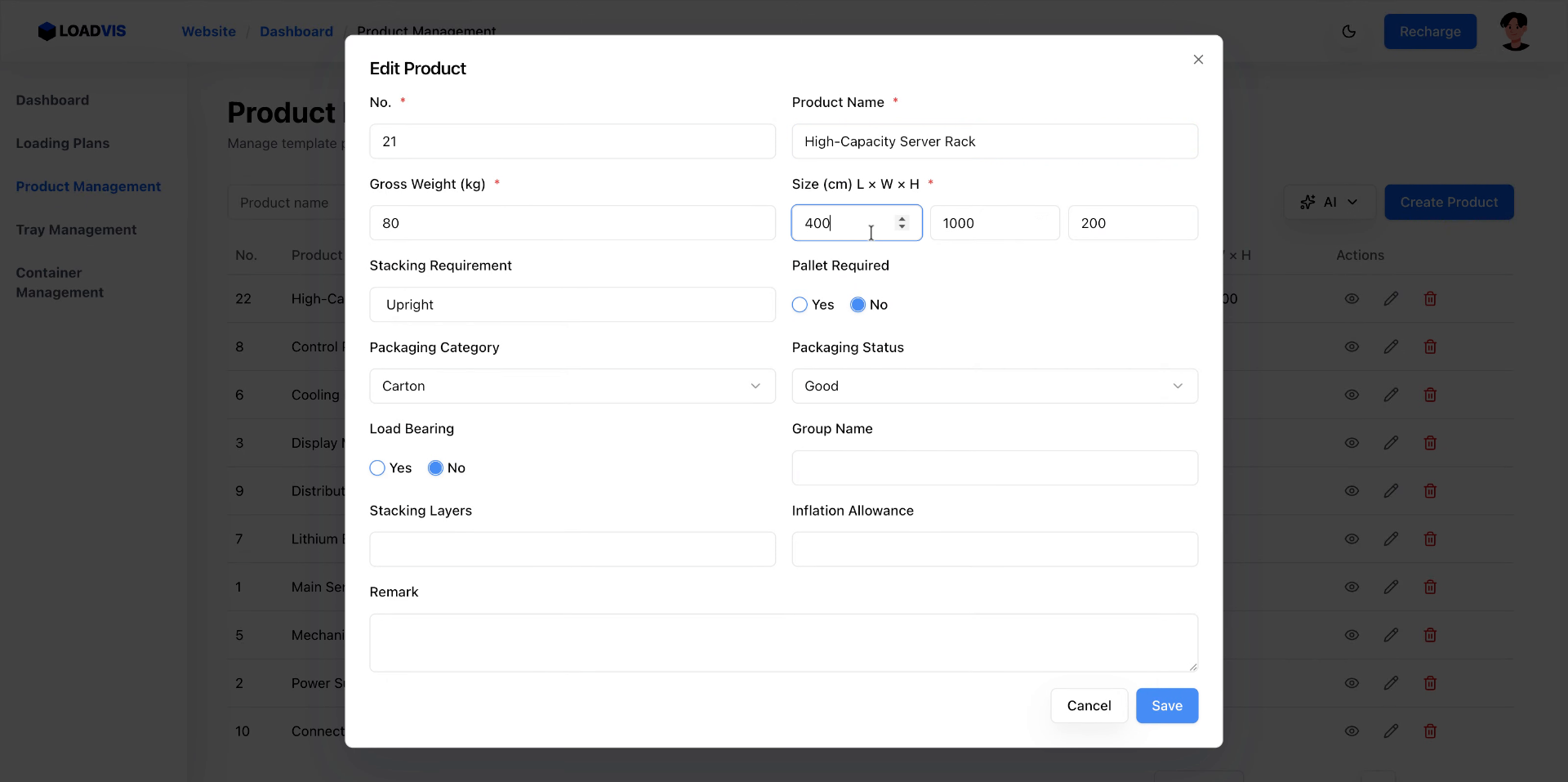
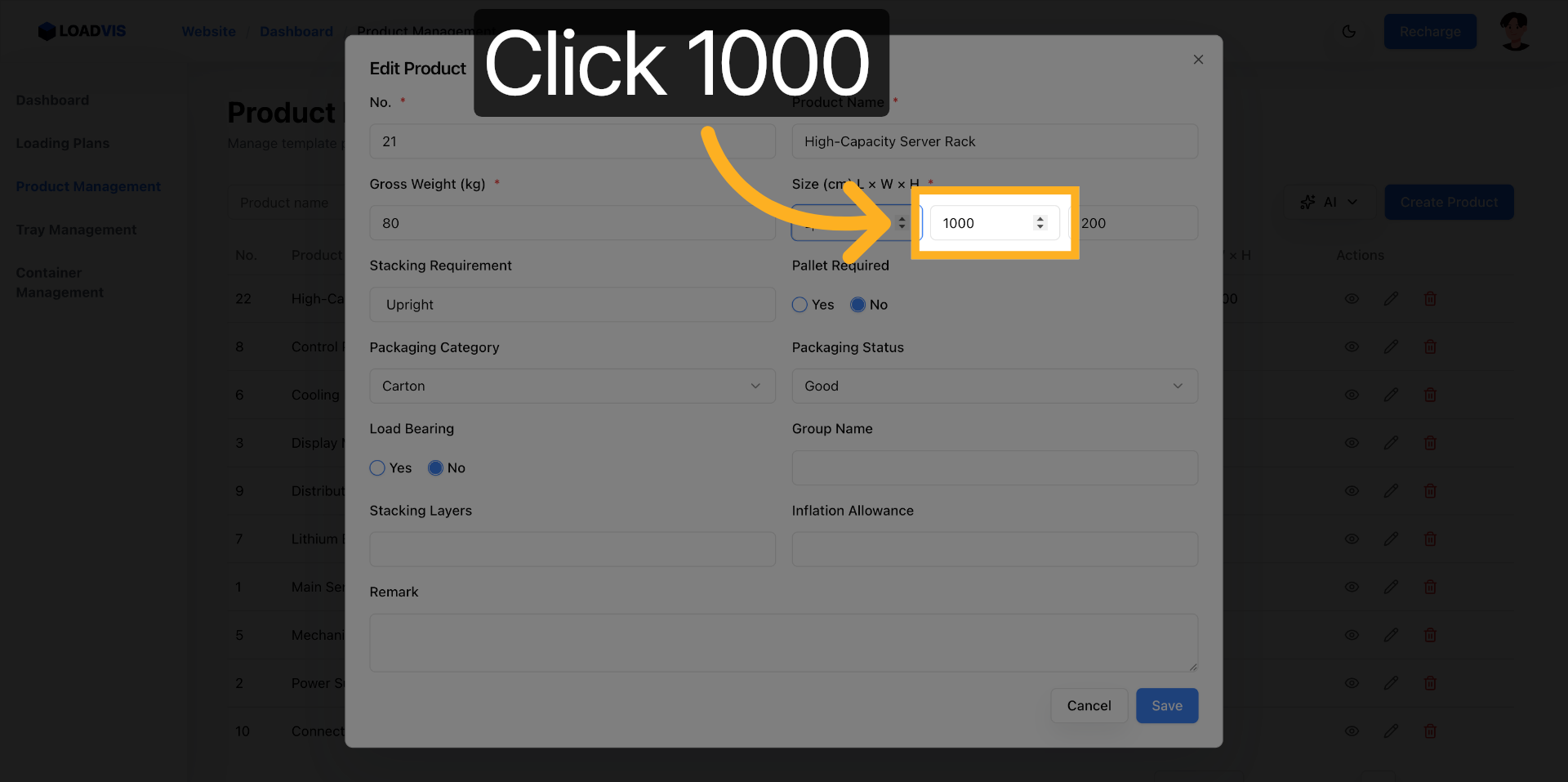
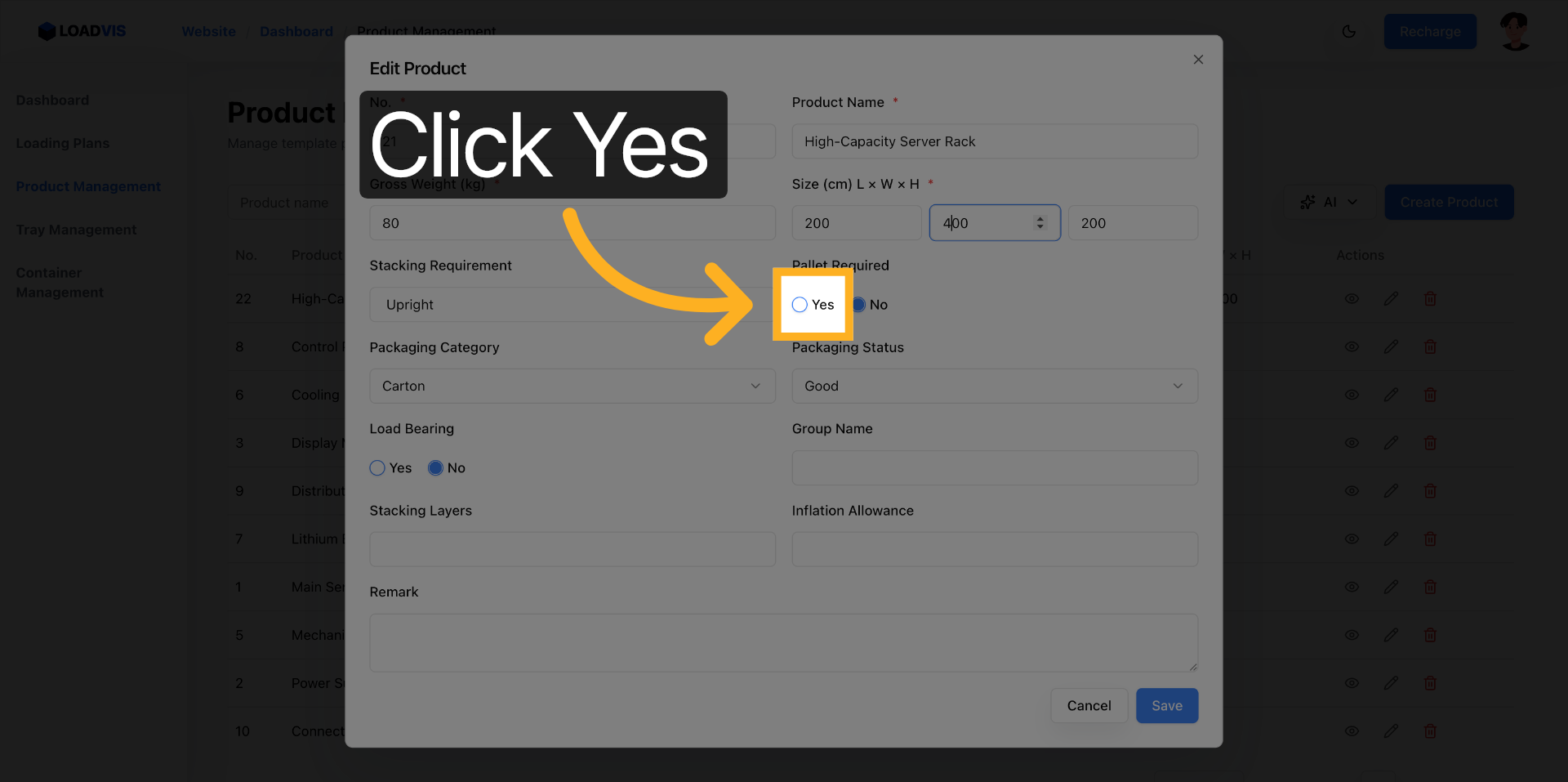
Il sistema propaga la modifica nel calcolo del caricamento. Non è un aggiornamento cosmetico. Ricalcola i vettori di forza. Salva. Verifica la lista. La ricerca per keyword non deve restituire record fantasmi. Filtra. Conferma. Chiudi il ciclo.
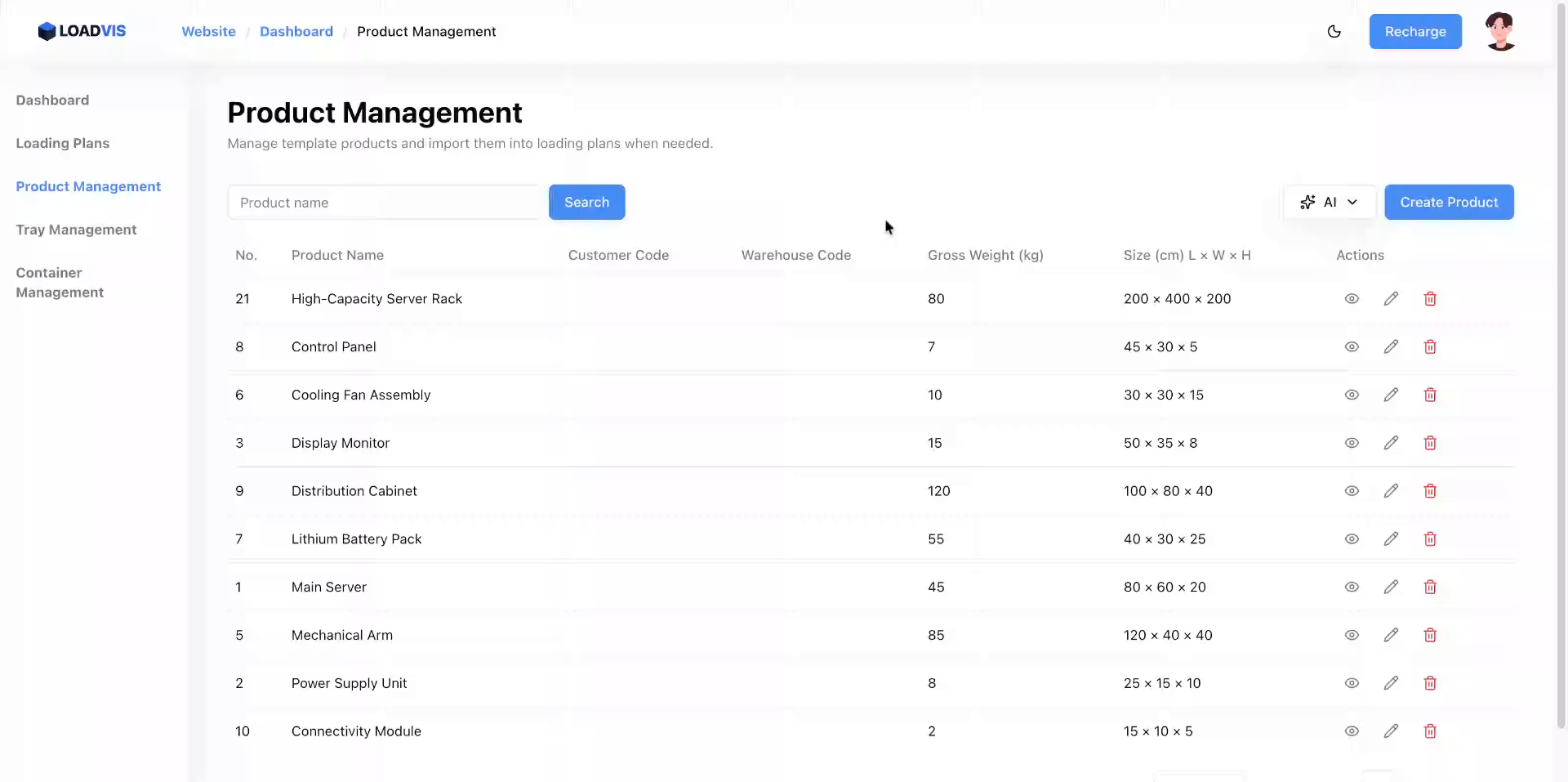
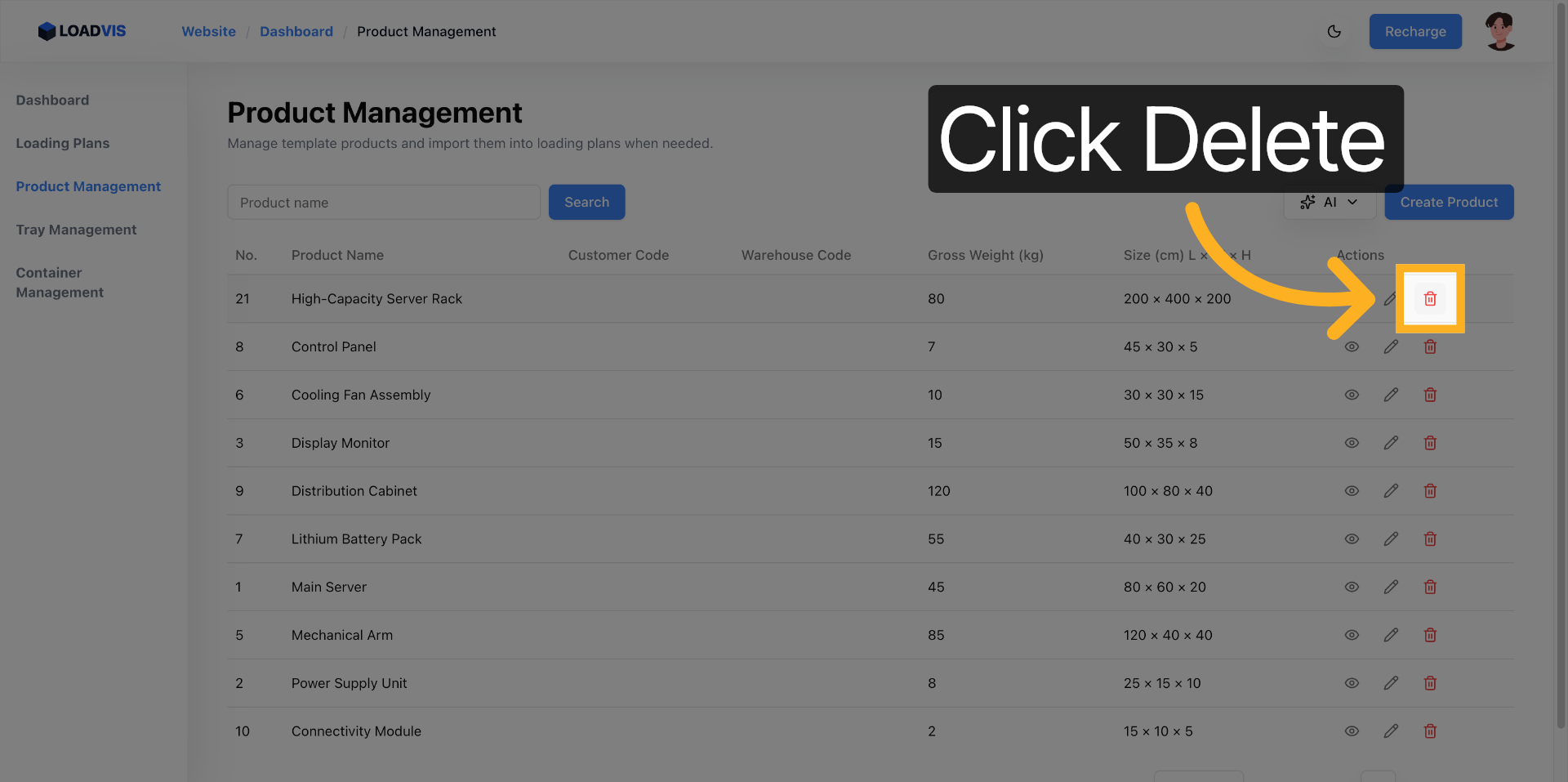
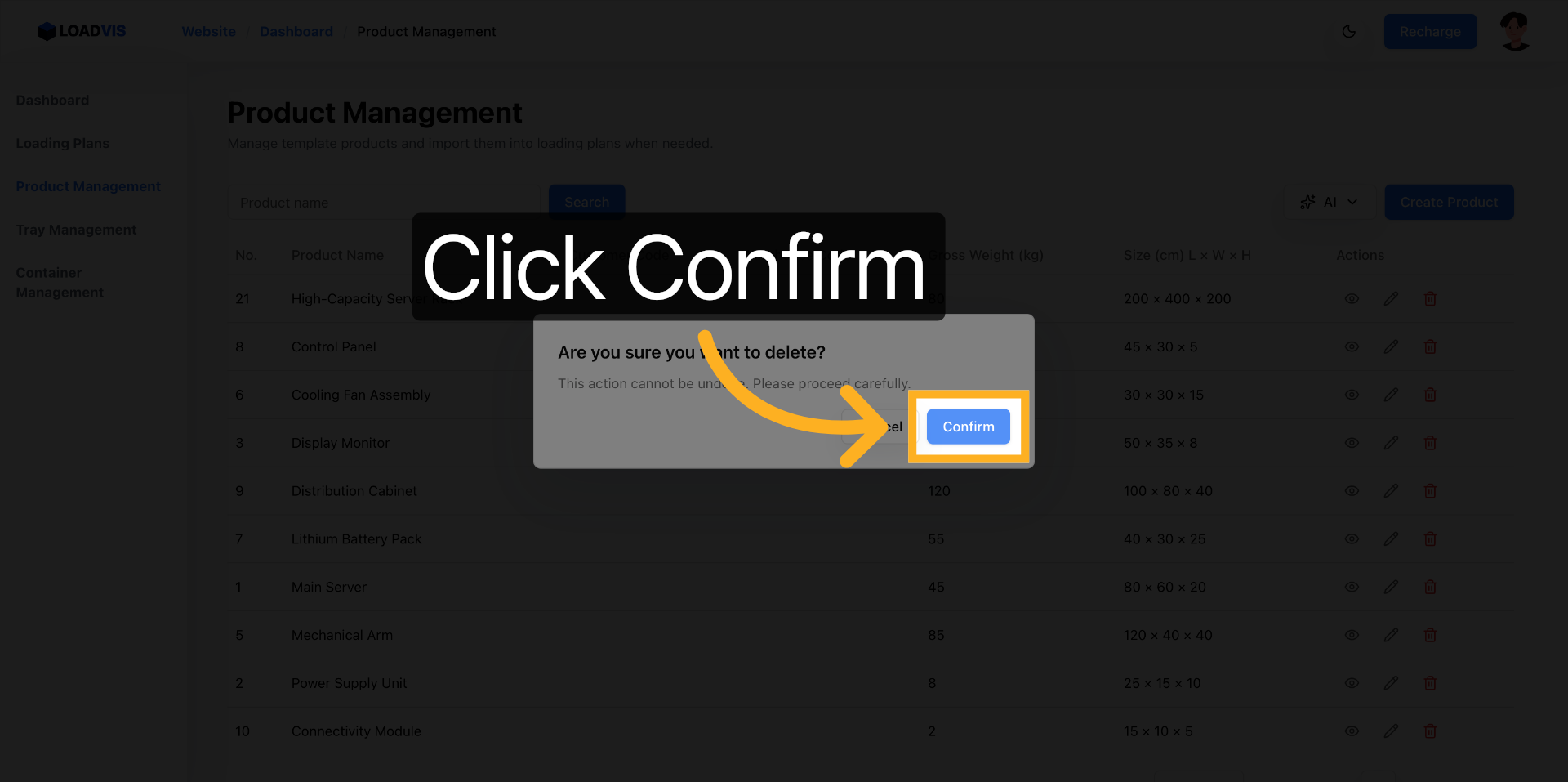
A volte un record va rimosso. Obsoleto. Errato. Non affidarti al soft-delete nascosto. L'interfaccia richiede una doppia conferma. Buona pratica. Evita il garbage accumulation nel DB che poi inficia le query di ottimizzazione.
Quando le cose vanno male? Succede quando il parser interpreta “max 1.5t per layer” come peso del singolo collo. Il carico collassa in simulazione. O peggio, in transito. Controlla manualmente i limiti di impilamento. Sempre. Confronta con il foglio tecnico originale. Non delegare al modello. L'automazione accelera l'acquisizione. La disciplina garantisce la stabilità. Niente di più. Niente di meno.