95% 적재율의 함정: 컨테이너 경계 데이터가 현장 실행을 무너뜨리기 전
물류 계획 대시보드에 뜬 94.5% 적재율 수치는 보기엔 흠집이 없다. 시스템은 수초 안에 파레트 배치 알고리즘을 돌렸고, 결과물은 수학적으로 매끈하다. 그런데 현장에서는 포크리프트가 컨테이너 도어 상단 램프에 걸려 멈춘다. 고작 4cm의 간섭이다. 시스템이 기록한 도어 개구부 높이가 실제 철제 프레임보다 높게 설정되어 있었기 때문이다. 축중 데이터도 마찬가진데. 운송사가 노선별 안전 마진을 10% 하향 조정했음에도 데이터베이스는 여전히 구형 중량 한도를 참조한다. 계산상 100% 미만으로 떨어졌으니 적재 지시가 나갔지만, 현장 검문에서 규정 위반으로 트레일러가 되돌아온다. 시뮬레이션의 정교함과 물리적 실행 가능성은 완전히 다른 차원에 존재한다. 우리는 종종 후자를 전자의 종속 변수로 착각하곤 한다.
왜 이 문제는 반복적으로 과소평가되는가
대부분의 담당자가 컨테이너를 ‘공장에서 규격화된 정적 객체’로 인식하는 경향이 강해서다. 20GP나 40HQ가 마치 ISO 표준을 그대로 찍어낸 블록인 양 다룬다. 현실은 훨씬 거칠다. 출고 연식, 운송사의 자체 보강재 도장 두께, 도어 실(seal)의 경화 정도, 심지어 내부 목재 패드의 마모에 따라 유효 치수는 3~8cm까지 요동친다. 중량 제한도 고정값이 아니다. 지역 도로법 개정이나 특정 항로의 임시 규제 변경이 발생하면 데이터는 하루아침에 폐기물이 된다.
“초기 설정 한 번으로 끝날 일”이라고 치부한 순간, 그 미세한 편차가 솔버 알고리즘의 출력값을 실행 불가능한 가상 시뮬레이션으로 전락시킨다. 데이터 레이어가 현실을 추종하지 않으면, 알고리즘은 그냥 정교한 계산기일 뿐이다. 오류는 언제 터지는가? 파싱된 값을 그대로 DB에 던져버리고 검증 동선을 건너뛸 때다.
워크플로 단계의 본질: 클릭이 아닌 ‘경계 조건’의 확정
가이드 화면에서 보이는 컨테이너 구성 작업의 핵심은 UI 조작 순서가 아니다. 경계 조건(boundary condition)을 어떻게 확정하느냐의 문제다.
비정형 사양서나 메일 스레드를 구조화하는 텍스트 파서 도구는 분명히 초기 입력 속도를 끌어올린다. 하지만 그 결과는 어디까지나 ‘초안’일 뿐이다. AI가 추출한 “내부 높이 266cm”라는 숫자를 그대로 영구 저장하는 건 위험한 도박이다. 도어 힌지나 상부 보강재가 실제 통행 가능 높이를 260cm로 깎아먹고 있다면, 알고리즘은 그 6cm의 물리적 마진을 절대 계산에 반영하지 않는다. 데이터의 정확도가 곧 계획의 실행 가능성이다.
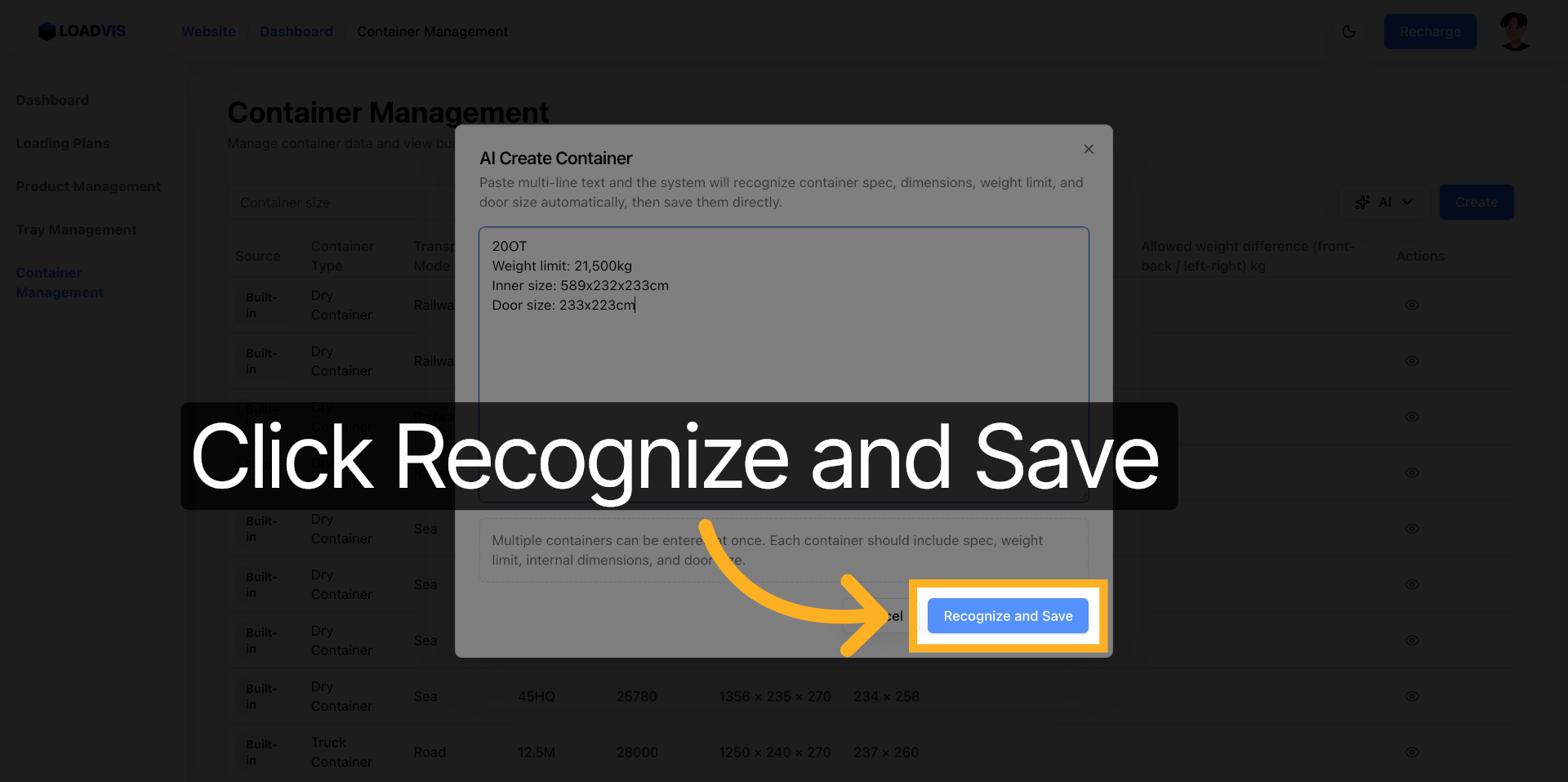
시스템에서 컨테이너 레코드를 생성할 때, AI 생성 버튼을 눌러 텍스트 블록을 집어넣는 건 첫 단계다. 입력 창에 "20OT 최대 중량: 21,500kg 내부 치수: 589×232×233cm 도어 개구부: 233×223cm" 같은 원문을 붙여넣으면 파싱 엔진이 키-값 쌍을 분리해낸다. 인식 및 저장을 누르는 시점은 오히려 운영자의 검증이 본격적으로 시작되는 신호다.
하지만 여기서 멈추면 안 된다. 생성 양식을 직접 열거나, 기존 레코드를 편집 모드로 전환해 도어 개구부 높이/너비, 내부 유효 치수, 정격 중량 한도를 실제 출하 조건과 대조해야 한다. 20OT 코드를 입력하고, 적재 한도 21500, 내부 치수 589×232×233을 각각 매핑하는 과정이 번거로울 수 있다. 하지만 필드에 직접 숫자를 매핑하는 이 단계가 시스템의 신뢰도를 가른다.
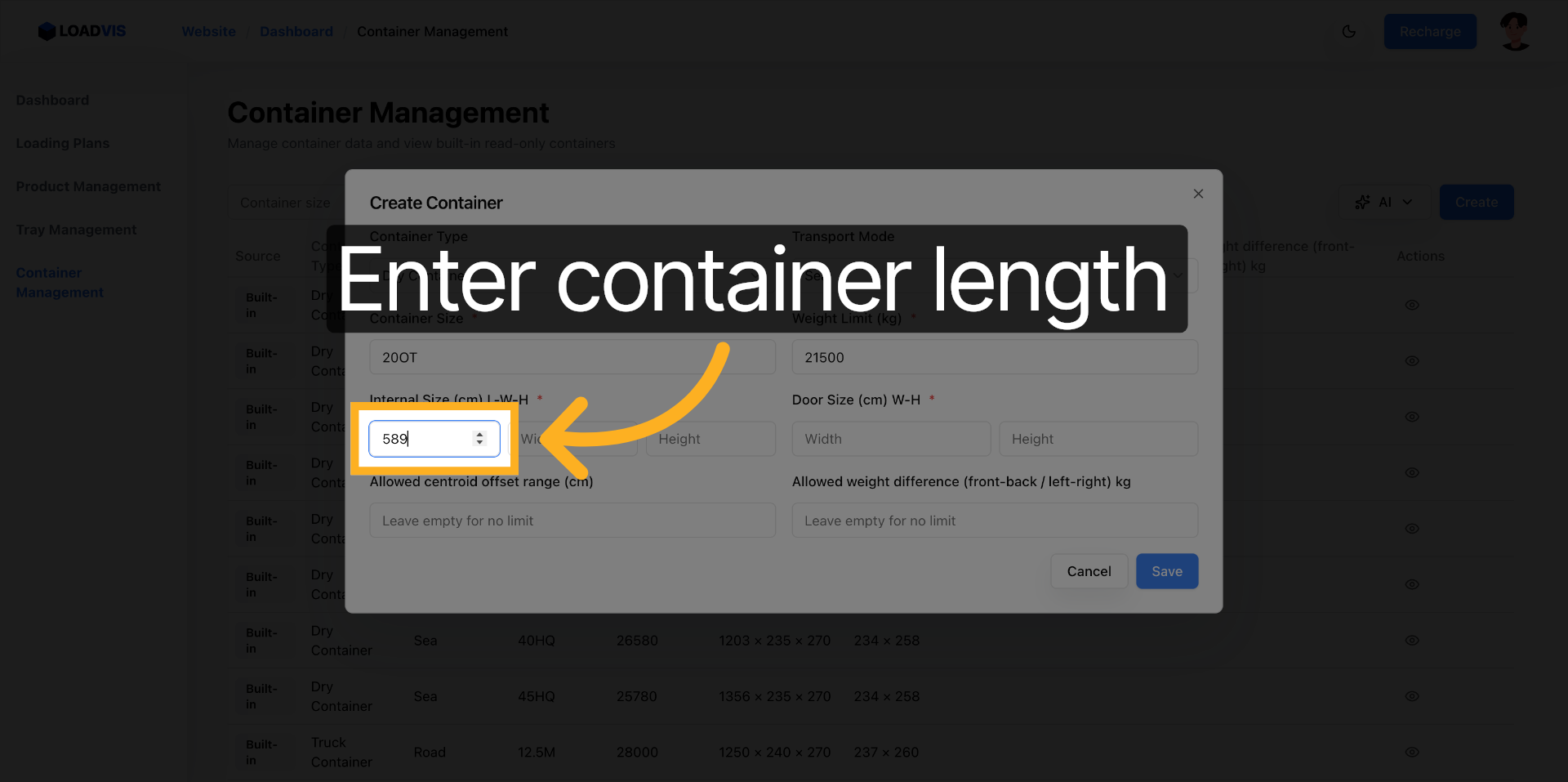
결정적으로 문 개구부 높이 필드에 도어 램프와 힌지 간섭을 고려한 실제 통과 가능 값을 입력해야 한다. 솔버는 주어진 매개변수 공간을 수학적으로 엄격하게 탐색할 뿐이다. 입력값이 물리적으로 가능하지 않다면, 최적해(optimization)는 즉시 무의미해진다.
잘못된 접근 방식 vs 더 확실한 방법
흔한 함정은 시스템 제공 기본 템플릿을 복사하거나, AI 인식 결과를 검토 없이 저장하는 패턴이다. 컨테이너 유형별 필터를 활용하지 않고 과거 데이터를 무시한 채 신규 레코드만 중복 적재하면, 데이터베이스는 순식간에 버전 충돌 덩어리가 된다. 레코드 간 충돌이 발생하면 계획 엔진은 어느 값을 기준으로 삼아야 할지 혼란에 빠진다.
더 단단한 접근법은 명확하다. AI 파싱 또는 수동 입력 후, 반드시 편집 플로우로 진입해 계약서상의 중량 제한과 현장 계측값을 교차 검증한다. 컨테이너 목록의 검색 필터를 활용해 동일 규격이라도 운송사나 계약 조건이 다르면 별도 레코드(Isolation)로 분리 관리해야 한다.
조건에 20GP를 입력하고 검색을 실행하면, 시스템은 조건 부합 레코드만 반환한다. 과거 계획에서 발생한 부적재나 중량 초과 이력을 피드백 루프로 연결해 매개변수를 주기적으로 보정하는 게 운영의 핵심이다.
특정 레코드를 선택하고 보기를 누르면 세부 사양이 확장된다. 이 시점에서 수치 이력이나 계약 만료 여부를 확인하지 않으면, 데이터는 또다시 허상화된다. 불필요하거나 폐기된 규격이 섞이면 안 된다. 삭제 버튼을 누르고 확인 창에서 재확인을 거쳐야 데이터베이스의 무결성이 유지된다.
도구가 해결해 줄 수 있는 범위와 수작업 검증의 필요성
자동화 모듈이 처리할 수 있는 범위는 정해져 있다. 비정형 텍스트의 구조화, 범위 기반 입력 검증, 중복 방지, 그리고 계획 알고리즘으로의 파라미터 연동은 매끄럽게 작동한다. 하지만 도구가 해결하지 못하는 영역이 명확히 존재한다. 현장에서 마주하는 물리적 변수는 소프트웨어가 예측할 수 없는 구간으로 작동한다.
- 물리적 마모 및 개조 감지 불가: 실제 컨테이너의 내부 패딩, 목재 보강재, 오래된 도어 경첩의 치수 변화는 시스템이 실시간으로 인식할 수 없다.
- 동적 계약 제한의 반영: 특정 항로의 일시적 중량 제한이나 특수 화물 취급 규정 변경은 외부 변수로 작용한다.
따라서 수작업 확인은 반드시 선행되어야 한다. 적재 계획 실행 전, 현장의 실제 도어 개구부 측정(실링 및 힌지 포함), 운송사 최신 사양서 대조, 중량 한도의 유효성 재확인이 필수 단계다. 시스템은 입력값에 대한 최적해를 제시할 뿐, 입력값 자체의 현장 적합성까지 책임지지 않는다.
데이터 관리 화면은 단순한 레지스트리가 아니다. 가상 계획과 현장 실행의 간극을 메우는 검증 인터페이스다. 자동화 기능이 입력 속도를 높일수록, 경계 조건에 대한 운영진의 검증 비중은 오히려 선형적으로 증가해야 한다. 계획의 성공은 알고리즘의 정교함보다 입력 데이터의 현실 반영도에 좌우되는 경우가 많다. 현장의 먼지와 계약서의 잉크가 시스템의 숫자와 맞닿을 때, 비로소 적재율은 의미가 생긴다.