Revue de scénario : Fiabilisation des paramètres de palettes pour l'exécution terrain
On optimise souvent le volume cubique en oubliant la physique. Erreur classique. Le solveur tourne, les cycles CPU s'enchaînent, et le plan de chargement sort propre sur le moniteur. Puis arrive le quai. Le chariot élévateur cale. La gerbe tangue. Pourquoi ? Parce que la fiche technique a été survolée. Les contraintes de charge statique, la tolérance d'empilage, le poids à vide du support… tout ça finit souvent dans des notes ou, pire, dans le vide. Un plan dense sur le papier devient un risque d'instabilité dynamique en condition réelle. L’alignement entre les données d’entrée et les capacités physiques du parc n’est pas optionnel. C’est une condition sine qua non. Voyons comment structurer cette phase de mapping sans se perdre dans l’automatisation aveugle.
Flux assisté : parsing sémantique et extraction d'entités
L'outil propose un moteur de reconnaissance textuelle. Il ne devine pas. Il isole des entités. Si le flux fournisseur vous renvoie un bloc de données brutes, le gain de temps est réel. Mais attention au bruit lexical. Le parser segmente, le système type, la persistance suit. Si l'entrée est chaotique, la sortie le sera aussi. C'est mathématique.
La procédure reste binaire. On bascule vers la zone de gestion dédiée. L'interface appelle la routine de création assistée.
Activation du flux. Le contexte se verrouille sur l'analyse structurelle.
L'interrupteur logique passe en position active. L'outil attend votre payload.
Confirmation du mode assisté. Le workflow se déplie.
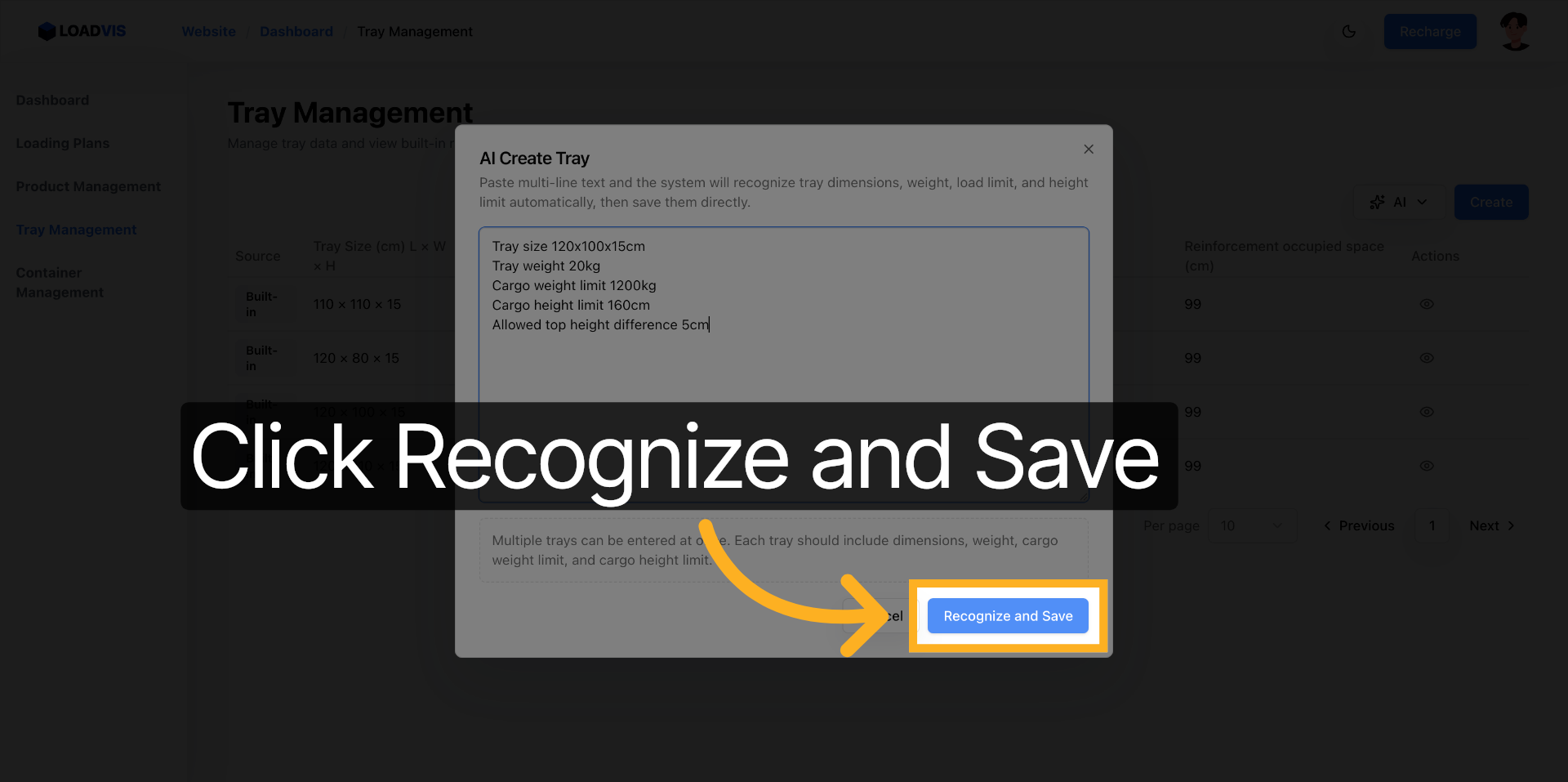
On injecte la chaîne brute directement dans le champ de saisie. « Dimensions de la palette 120×100×15 cm, poids à vide 20 kg, charge maximale 1 200 kg, hauteur max 160 cm, tolérance 5 cm ». Le tokenizer découpe les tuples, identifie les unités implicites, et mappe les seuils vers les champs du schéma. Le gain est net. L'ambiguïté, elle, reste possible.
« Reconnaître et enregistrer ». L'action déclenche la validation des types, vérifie les bornes min/max, puis commite la transaction en base. Le problème surgit quand le modèle confond hauteur du support avec hauteur maximale gerbée, ou quand il interprète une « charge à rupture » comme une « charge d'utilisation ». L'IA ne connaît pas les normes de manutention. Le système applique juste une logique stricte. La vérification post-extraction n'est pas une option. C'est le seul filet de sécurité viable avant de lancer le calcul de chargement.
Saisie impérative : contourner l'automatisation quand la donnée est fragmentée
Parfois, le fournisseur envoie un PDF scanné. Ou un tableau Excel avec des colonnes fusionnées et des notes de bas de page contradictoires. Le parser va échouer. On repasse en manuel. C'est plus lent. C'est aussi plus sûr. On contrôle chaque borne. On élimine l'interprétation algorithmique.
L'accès se fait par la même porte d'entrée.
Navigation vers le gestionnaire de configurations. La liste des entrées s'affiche.
Déclenchement du formulaire vierge. Le contexte d'écriture s'ouvre.
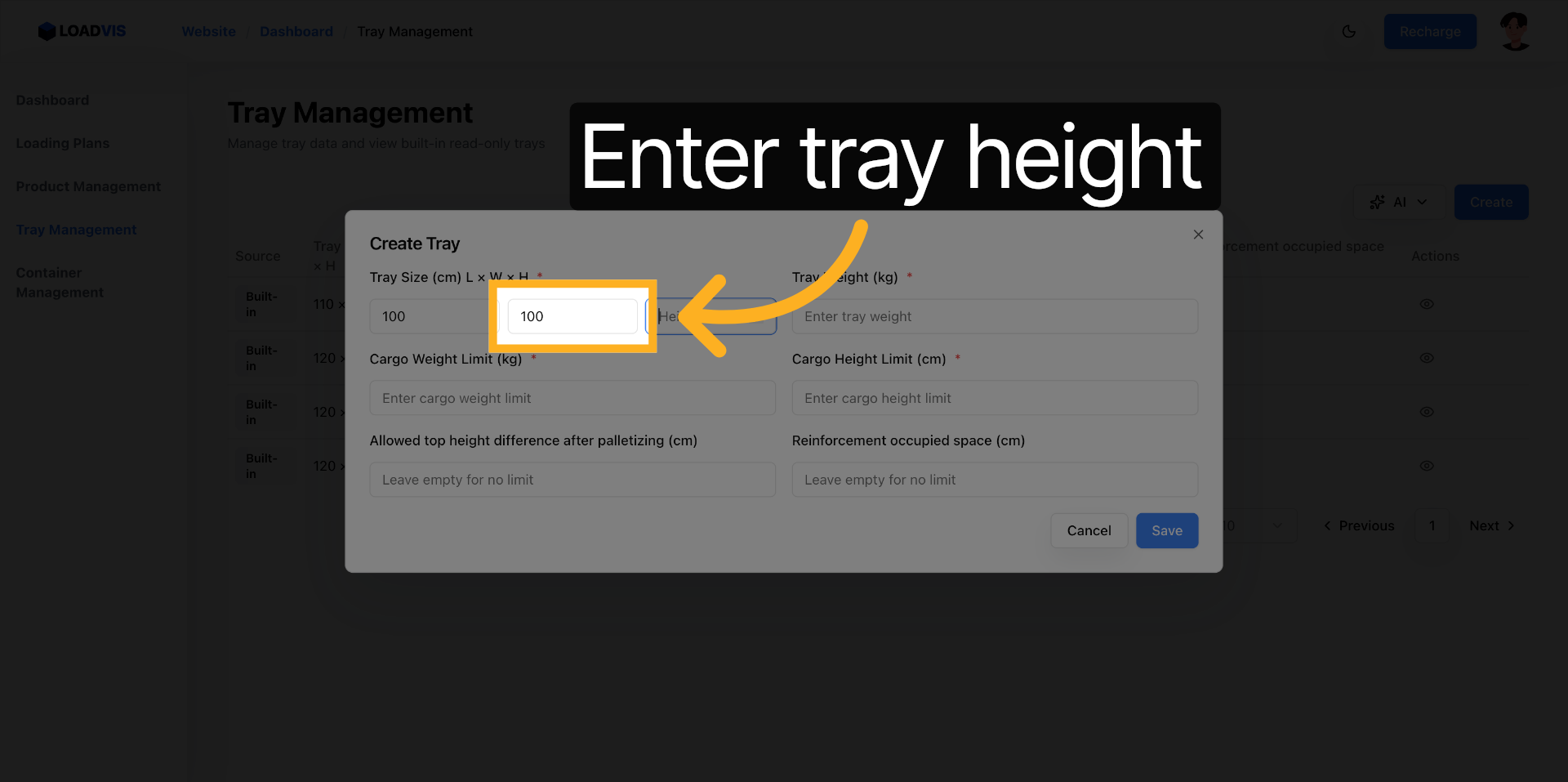
Le mapping demande de la précision métrique. Largeur injectée : 100 cm. L'unité est critique pour les calculs de volume et de stabilité latérale.
Hauteur définie : 100 cm. La dimension verticale dicte les contraintes sous portique et la hauteur de gerbage théorique.
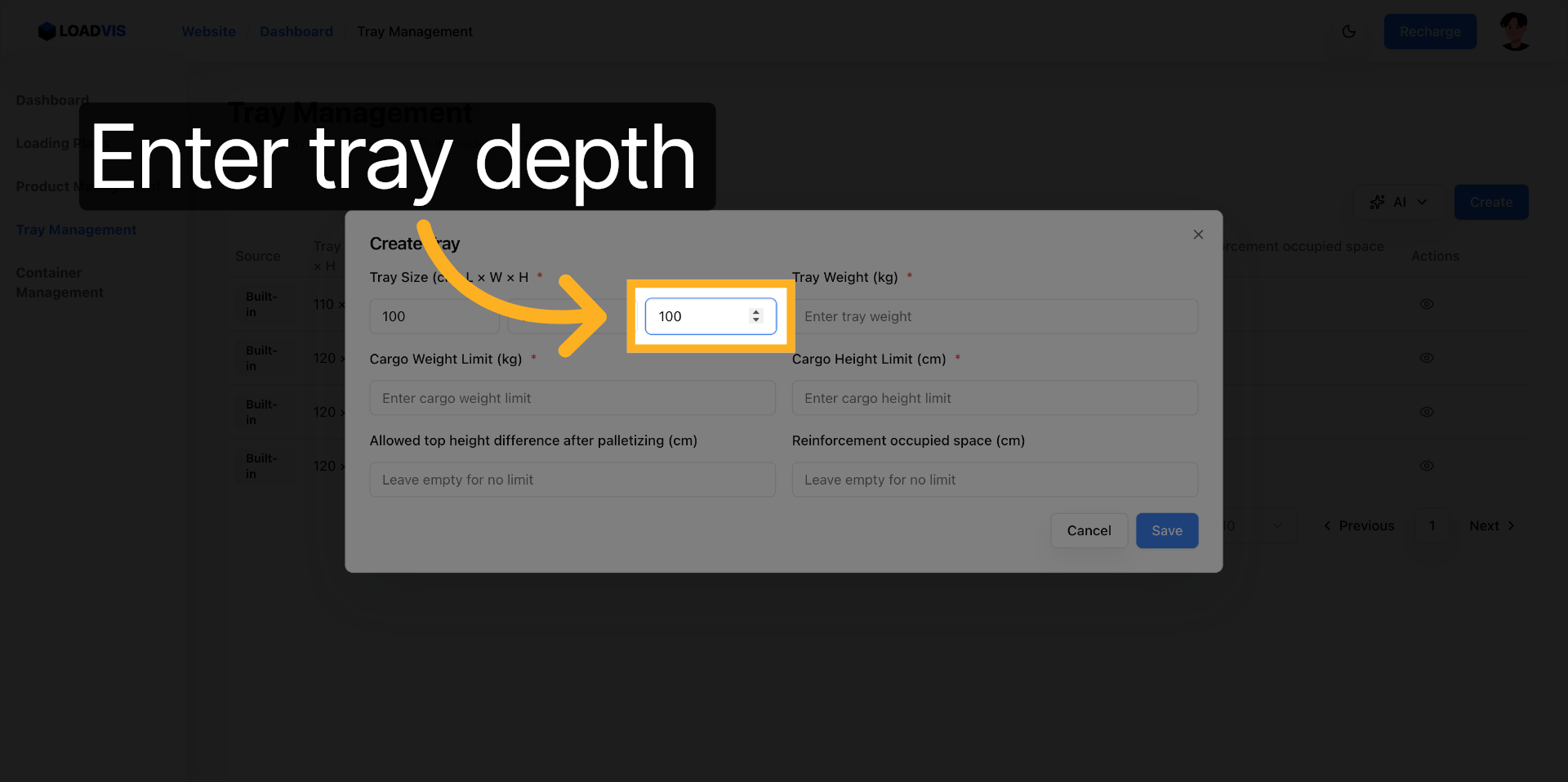
Longueur saisie : 100 cm. Le footprint est ainsi fermé.
Le poids propre du support. 200 kg. Cette valeur est soustraite de la charge maximale autorisée sur les axes du camion. Une erreur de zéro ici fausse toute la distribution des masses.
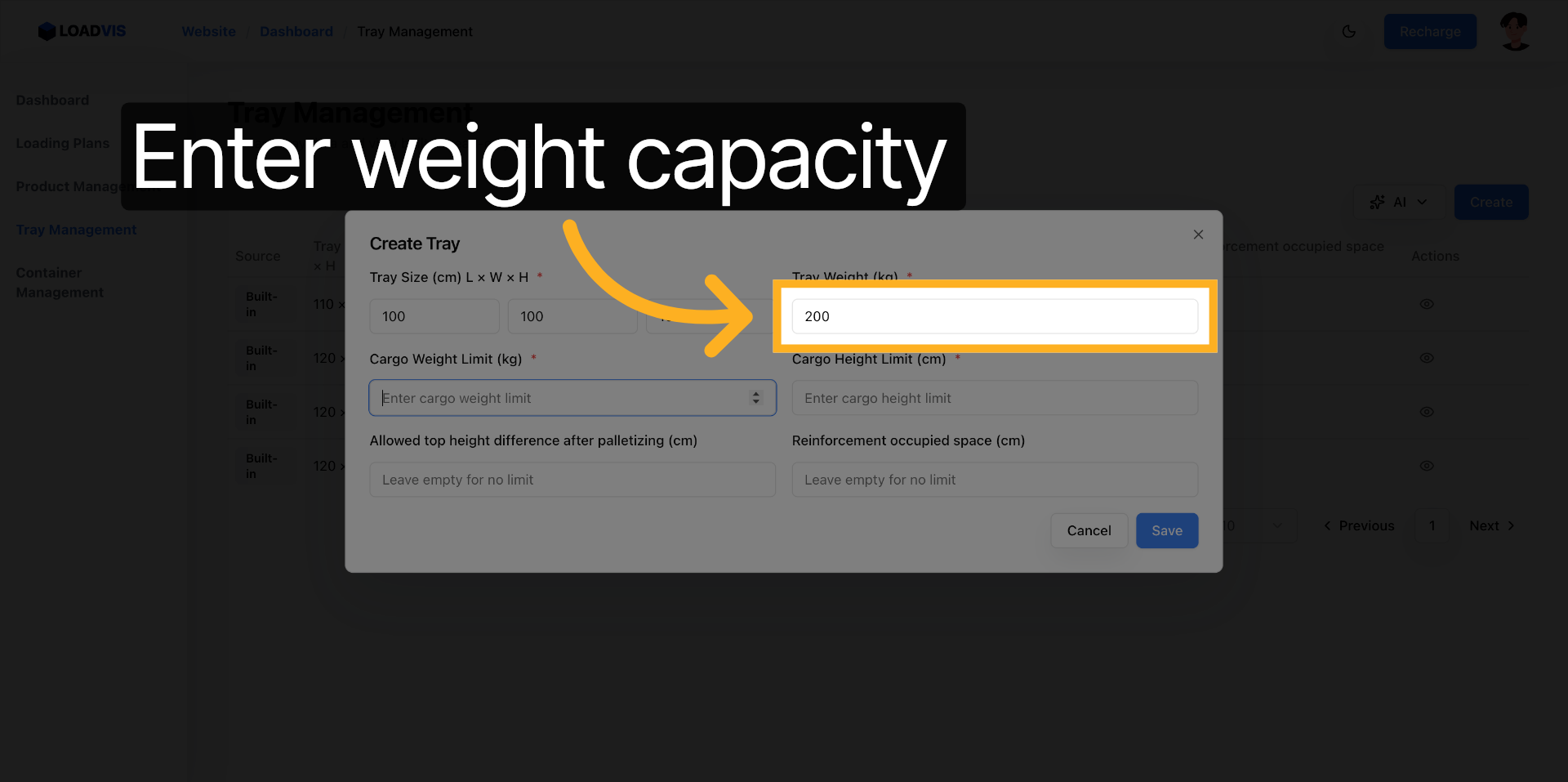
La charge maximale nominale de fret. 300 kg. La limite structurelle est posée.
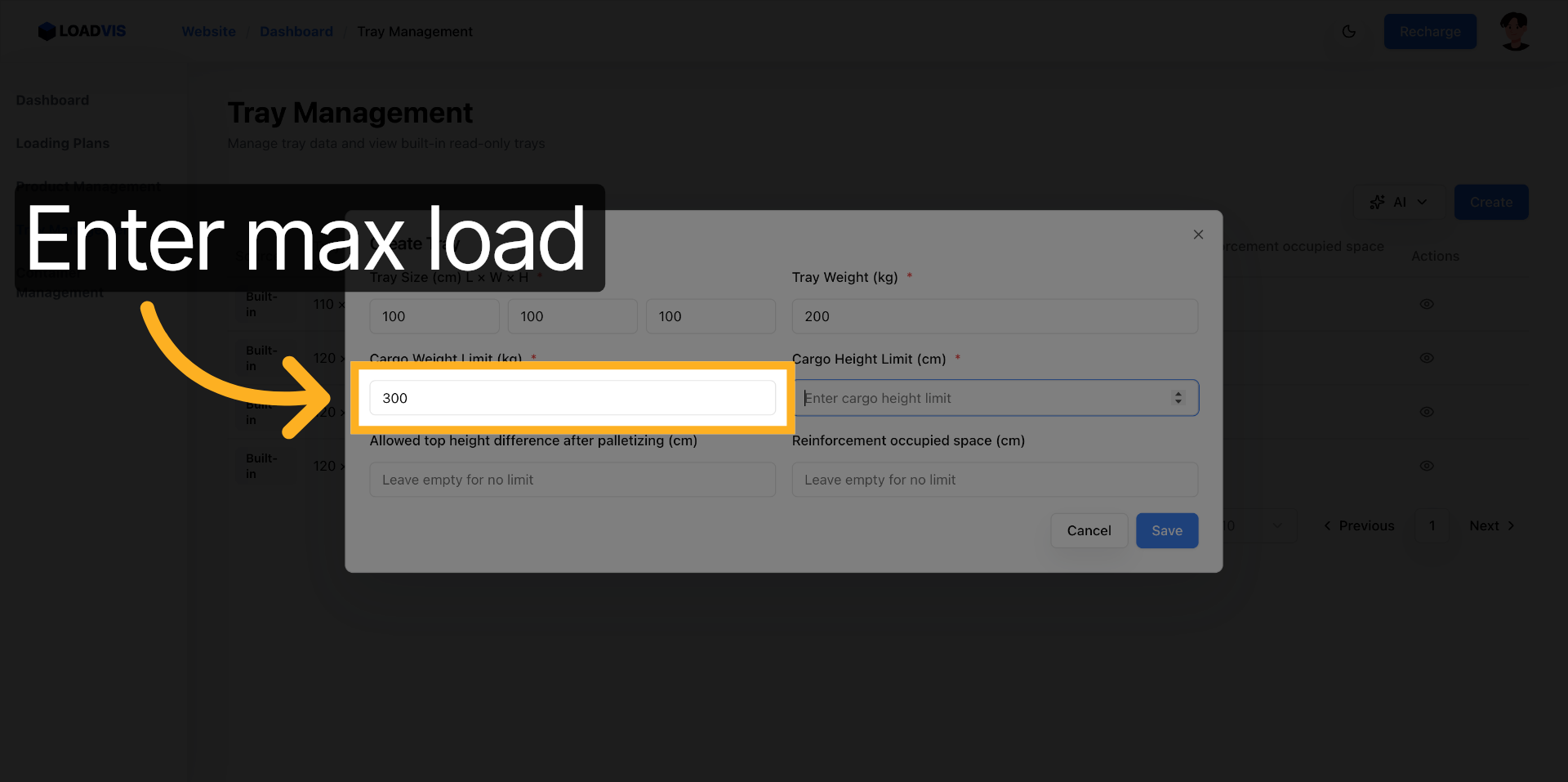
Vérification visuelle de la valeur injectée. 300. La cohérence est actée.
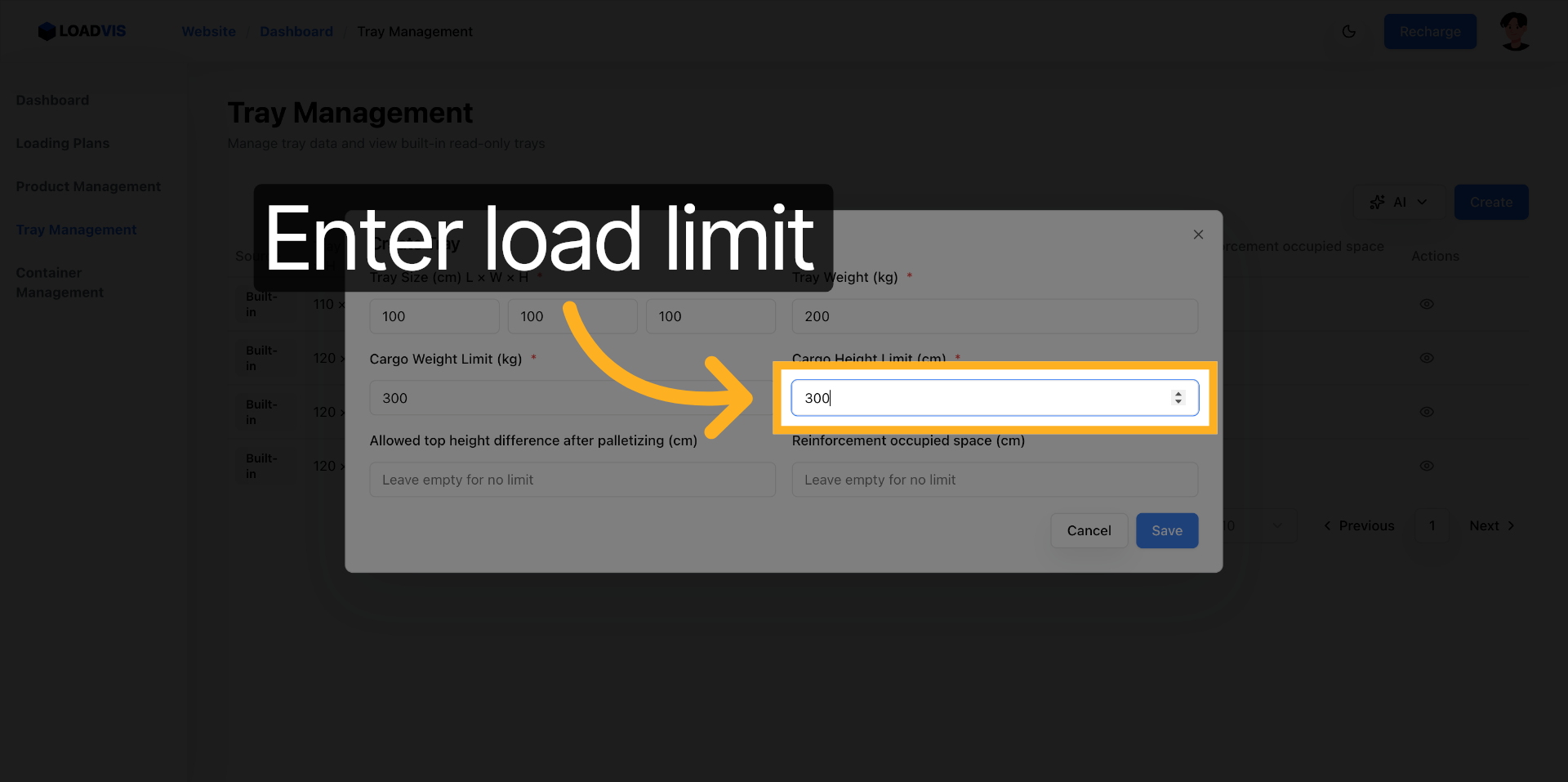
Commit. Le validateur backend vérifie l'intégrité du schéma, écrit les données et retourne un statut 201.
Pourquoi ce détail manuel ? Parce que les algorithmes de bin packing utilisent ces valeurs pour calculer les vecteurs de force, les centres de gravité et les points de basculement potentiels. Un millimètre décalé ou une confusion cm/mm décale tout l'équilibre. La saisie directe élimine le bruit sémantique. On tape ce qu'on a mesuré sur le sol. Pas ce qu'un script a supposé dans un JSON.
Audit des spécifications et ajustement des contraintes structurelles
La donnée n'est pas statique. Un lot de palettes usées perd sa rigidité. Les spécifications fournisseurs évoluent. Les tolérances de gerbage changent avec les normes de sécurité. Il faut consulter. Puis recalibrer. Le système expose les entrées, mais l'analyse humaine doit rester dans la boucle.
L'accès au gestionnaire reste le point d'ancrage.
Navigation vers la liste complète. L'inventaire est structuré.
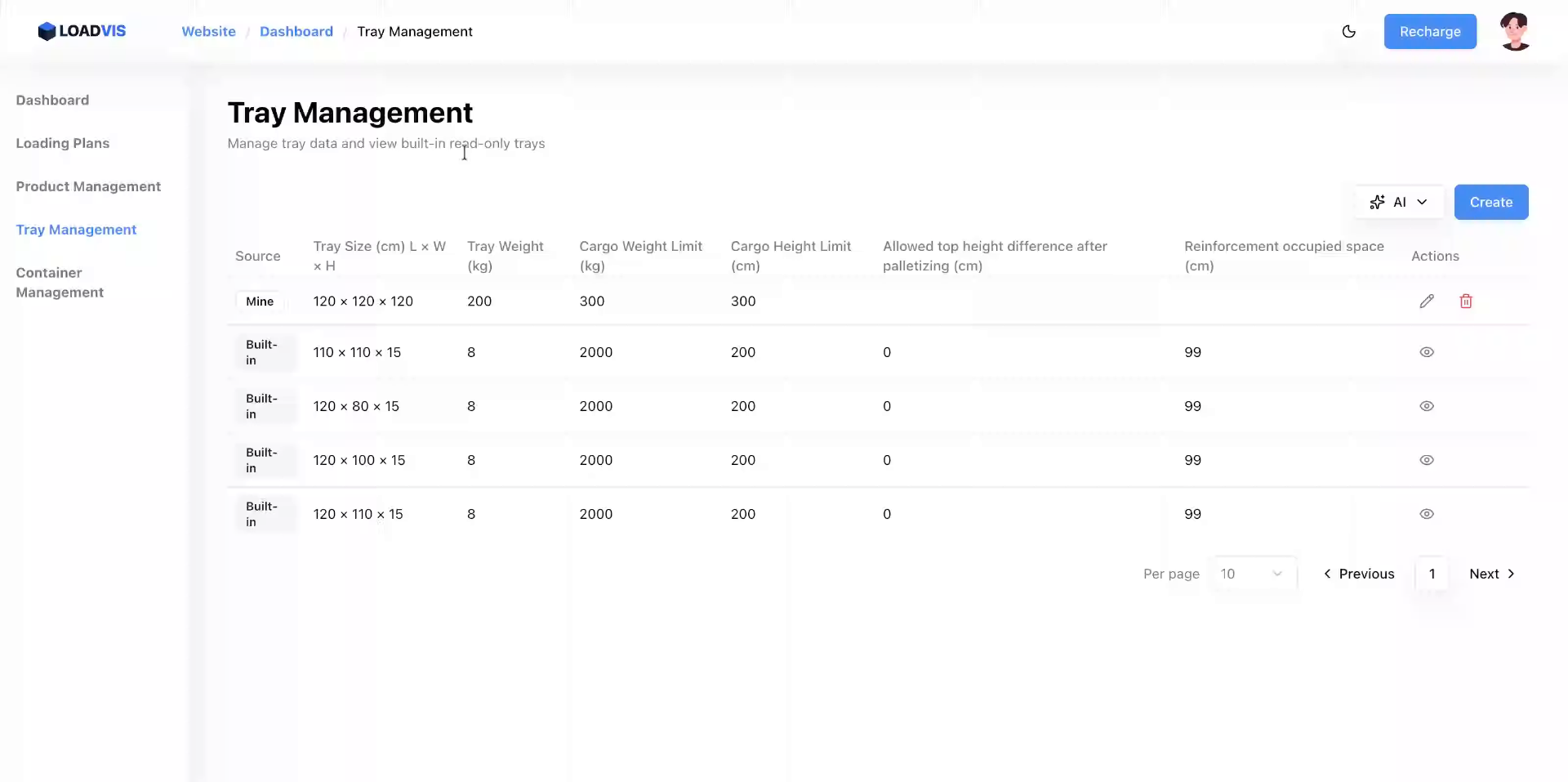
Expansion du nœud via « Afficher ». Le rendu expose les bornes de charge, les tolérances verticales et les dimensions brutes sans filtre. C'est ici qu'on confronte la base à la réalité du parc.
Fermeture du panneau. Retour à la grille. L'opération est légère en ressources, lourde en conséquence.
La modification suit exactement la même logique.
Ouverture du module de gestion. Le contexte d'édition se prépare.
Passage en écriture via « Modifier ». Le formulaire passe en état dirty, tous les champs deviennent mutables.
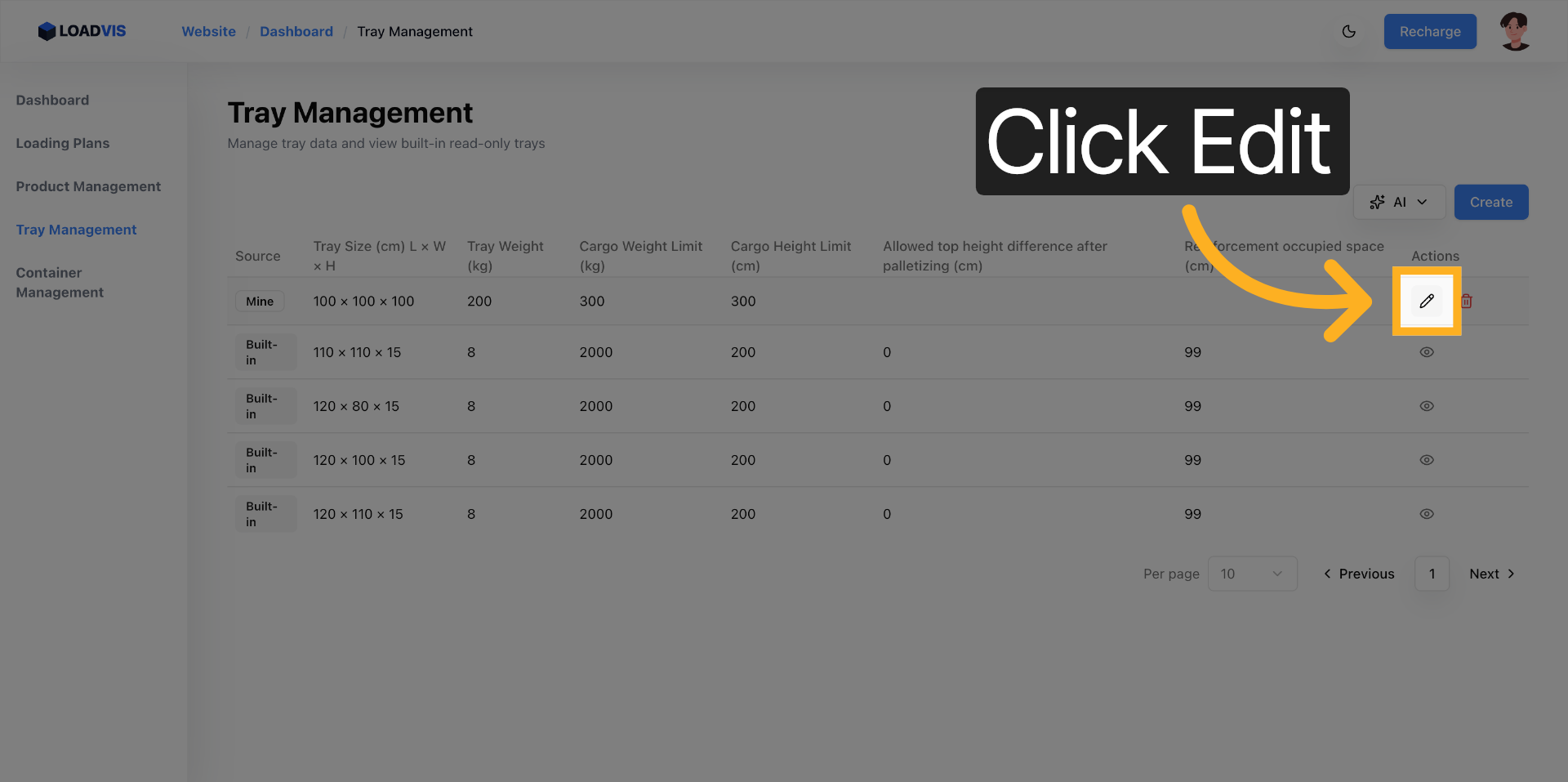
Mise à jour de la largeur. 120 cm. Le footprint s'élargit.
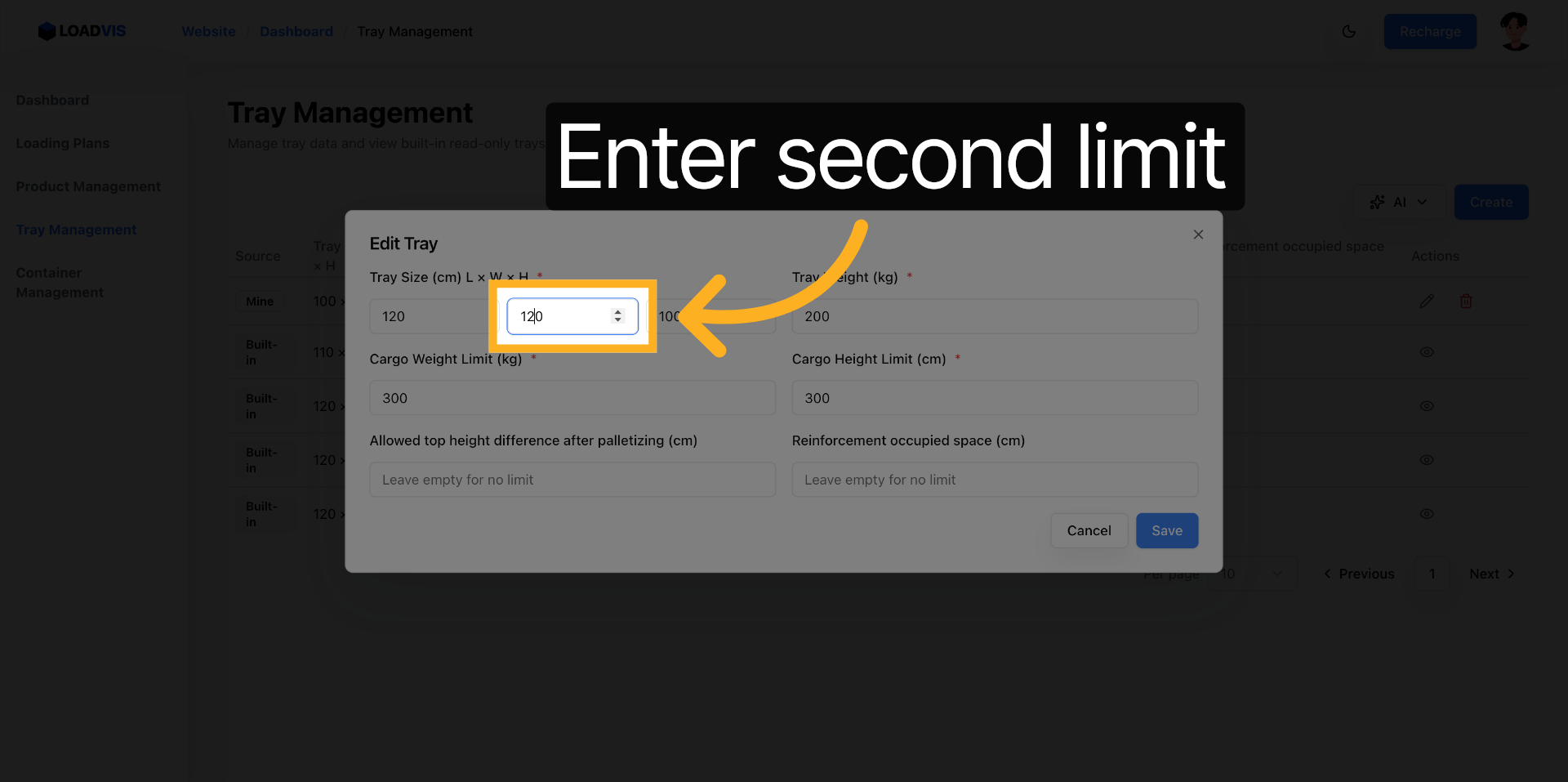
Ajustement de la hauteur. 120 cm. La contrainte verticale suit le mouvement.
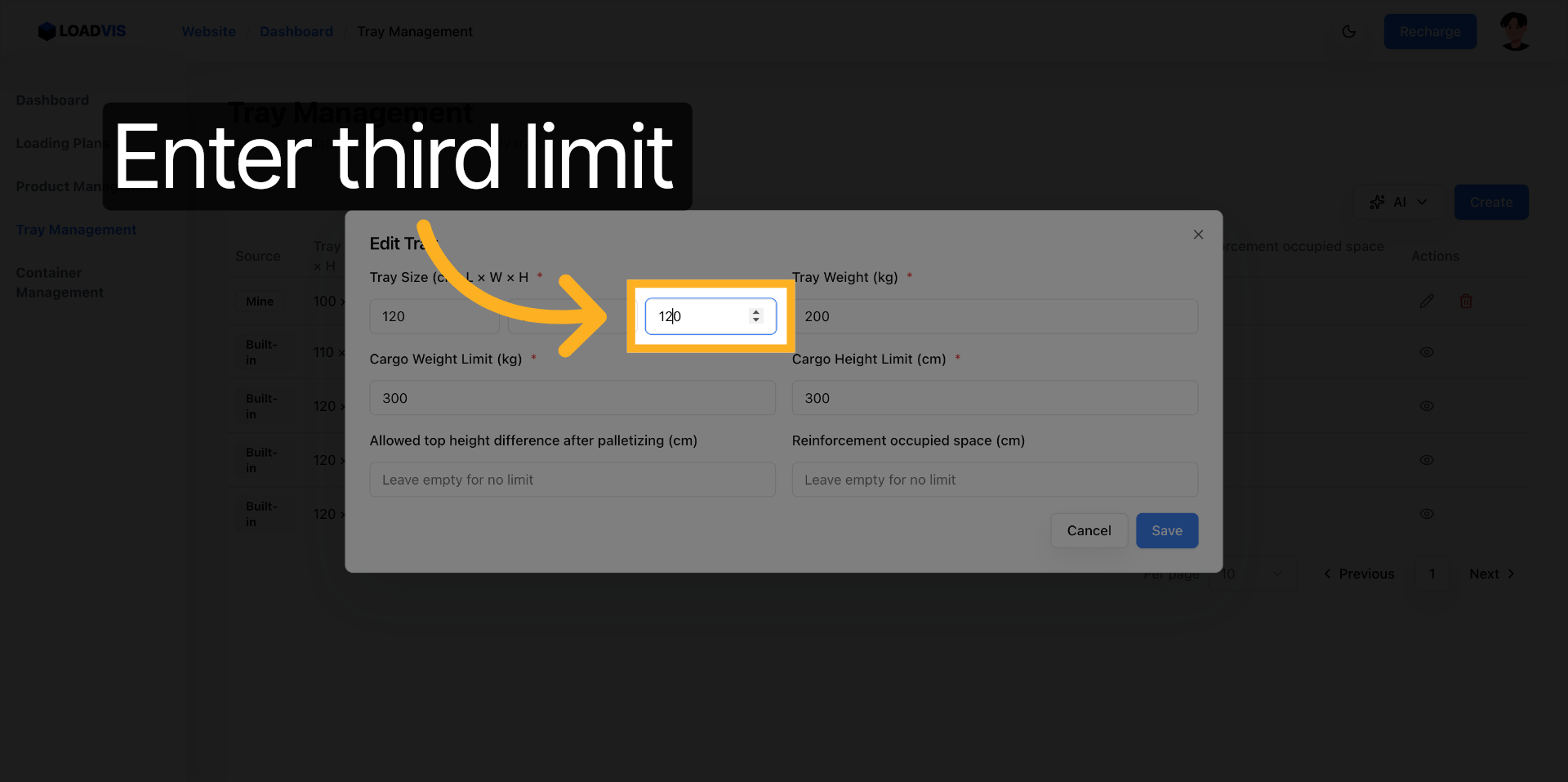
Le dégagement de renfort reste intentionnellement vide. Aucune restriction de dégagement structurel n'est appliquée. Le moteur de calcul considérera cette dimension comme non contraignante lors de l'optimisation.
Validation. Le système réécrit le tuple en base de données. Il invalide les caches de calcul locaux et prépare la propagation des nouvelles contraintes vers les instances de chargement en attente.
Ce qu'il faut vérifier manuellement avant de publier : la cohérence entre la hauteur déclarée et la hauteur maximale autorisée sous les linteaux de portes ou les racks d'entrepôt. Une correction tardive peut invalider des plans déjà validés par les équipes logistiques. Vérifiez l'impact sur les jobs en cours de calcul. Ne forcez jamais une mise à jour sans snapshot préalable.
Purge et gestion du cycle de vie des entrées
On accumule. Des palettes périmées, des prototypes de test, des doublons issus d'appels API répétés en staging. La base de données grossit. La latence des requêtes d'interrogation augmente. Les jointures deviennent lourdes. Il faut nettoyer. La maintenance n'est pas cosmétique. Elle est opérationnelle.
Vue d'ensemble du processus de retrait sécurisé.
Accès à la liste des assets. L'inventaire est exposé.
Sélection de l'action de suppression sur la ligne cible. Le système intercepte la requête DELETE et affiche une boîte de confirmation. Le verrouillage double évite la suppression par clic erroné sous pression de production.
Exécution. L'opération est irréversible au niveau du stockage transactionnel. L'enregistrement disparaît du schéma actif et libère les index associés.
La limitation technique est évidente : une suppression supprime les références logiques si les contraintes de clés étrangères ne sont pas configurées en cascade. Si un solveur ou une API tierce référence encore cet ID, il retournera une erreur 404 ou un IntegrityError au prochain appel. Préparez un plan de migration ou désactivez d'abord les jobs liés. Le nettoyage doit suivre une politique de rétention stricte, pas une impulsion ponctuelle après une réunion.
Synthèse technique
L'outil accélère la saisie. Il ne remplace pas la rigueur terrain. Les données structurées alimentent des algorithmes d'optimisation qui ne tolèrent aucune approximation numérique. Un poids à vide erroné fausse la charge utile disponible. Une tolérance de gerbage omise génère des collisions mécaniques en entrepôt. La création assistée, la saisie manuelle, l'audit ou la purge : chaque étape exige une validation croisée avec les fiches techniques et les capacités physiques du parc. Testez les limites. Confrontez le plan virtuel aux contraintes du quai. C'est la seule façon de faire passer l'optimisation de la théorie algorithmique à l'exécution concrète.