컨테이너 적재 계획, 85% 체적률도 현장을 통과하지 못하는 이유
알고리즘이 뱉어낸 최적화 시트에는 항상 매혹적인 숫자가 찍혀 있습니다. "20피트 컨테이너 적재율 88%, 중량 한계 내 완료." 수학적으로는 흠잡을 데 없죠. 그런데 현장의 포크리프트가 도어 입구에서 핸들을 꺾는 순간, 그 계획표는 물리적으로 멈춰 섭니다. 왜일까요? 계산식과 실제 적재 가능 영역 사이에는 보이지 않는 균열이 도사리고 있습니다. 도어 프레임의 미세한 경사, 내부 바닥 레일의 유효 높이, 운송 차량의 축중 제한. 이 변수들은 대부분 입력 단계에서 생략되거나, 매뉴얼의 공칭 수치로 덮여버리죠. 커피 잔을 식히며 현장 기록장을 훑어보면, 최적화 엔진이 좌초하는 지점은 연산 속도나 코어 로직이 아닙니다. 전제 조건 자체가 현장과 동떨어졌기 때문입니다.
시나리오 및 문제 정의
"20피트 컨테이너 적재율 88%, 중량 한계 내 완료." 알고리즘이 도출한 계획표는 수학적으로 완벽합니다. 하지만 현장 포크리프트가 진입하는 순간, 계획은 물리적으로 멈춥니다. 화물이 도어 프레임 상단에 걸리거나, 내부 바닥 레일 높이가 고려되지 않아 실제 유효 공간이 부족해지는 경우입니다. 혹은 AI가 매뉴얼에서 최대 적재량 21,500kg을 정확히 파싱했지만, 현장의 운송 차량 축중 제한이나 컨테이너 바닥 노후화로 인해 해당 수치가 실제 운영에서 불가능한 경우입니다. 체적 계산과 실제 적재 가능성 사이의 괴리는 단순한 오차가 아니라, 계획 단계에서 누락된 '물리적 경계조건'에서 비롯됩니다.
왜 이 문제는 지속적으로 과소평가되는가
대부분의 적재 계획은 표준 ISO 규격(예: 20GP, 40HQ)의 공칭 치수만으로 시작됩니다. 실무자는 "표준 규격이면 다 유사할 것"이라는 가정하에, 도어 개구부 실제 통과 높이/너비, 내부 마감재 두께, 실제 중량 한계를 별도 변수로 분리하지 않습니다. 또한 AI 기반 데이터 파싱이나 템플릿 호출이 편리해질수록, 입력값 자체의 현장 검증 단계가 생략되는 경향이 있습니다. 이는 계산상으로는 유효하지만, 현장에서는 실행 불가한 '종이 위의 최적화'를 반복적으로 양산합니다. 데이터의 정확성은 알고리즘의 연산 속도를 결정하지 않습니다. 입력된 전제 조건이 현장의 물리적 한계를 얼마나 충실히 반영하느냐가 실행 가능 여부를 결정합니다.
핵심 작업: 클릭이 아닌 물리적 룰셋 정의
워크스페이스의 컨테이너 관리 모듈(AI 파싱, 수동 생성, 매개변수 편집)은 단순한 데이터 입력 창이 아닙니다. 이는 적재 알고리즘이 작동하는 물리적 전제 조건을 정의하는 과정입니다. 화면을 클릭해 데이터를 흘려보내는 행위가 아니라, 현장의 물리적 경계선을 시스템이 이해할 수 있는 제약 조건으로 고정하는 작업이죠.
실제 운영 환경에서 이 경계선을 어떻게 정의해야 하는지, 단계별로 짚어보겠습니다.
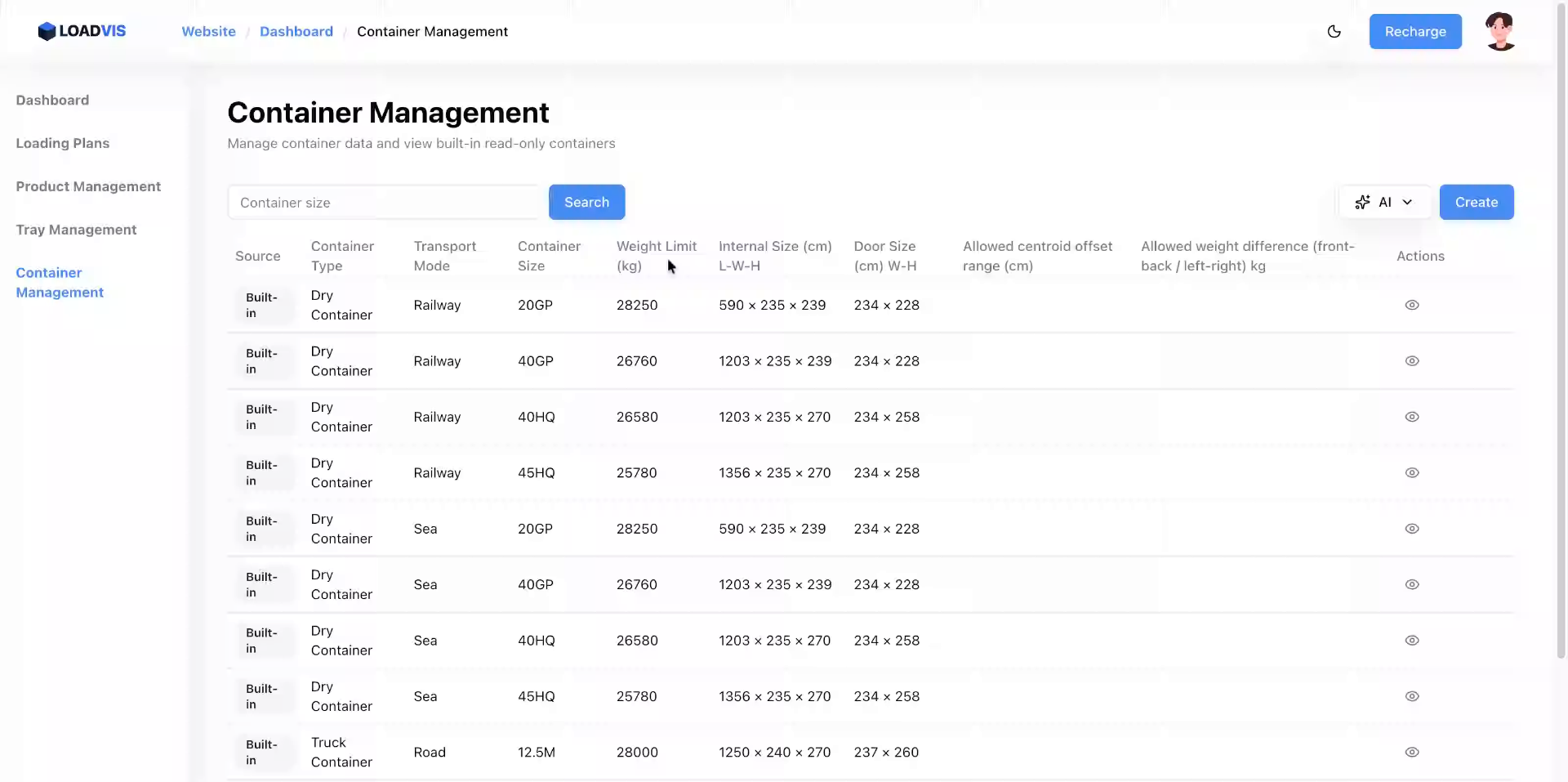
1. 도어 개구부 치수 분리 입력 내부 치수와 도어 치수는 명확히 다릅니다. 파싱 또는 생성 시 내부 공간(예: 589×232×233cm)과 별도로 도어 개구부(예: 233×223cm)를 반드시 명시해야 합니다. 이는 장비 진입 경로, 팔레트 회전 반도, 적재 순서 결정의 1차 물리적 장벽입니다.
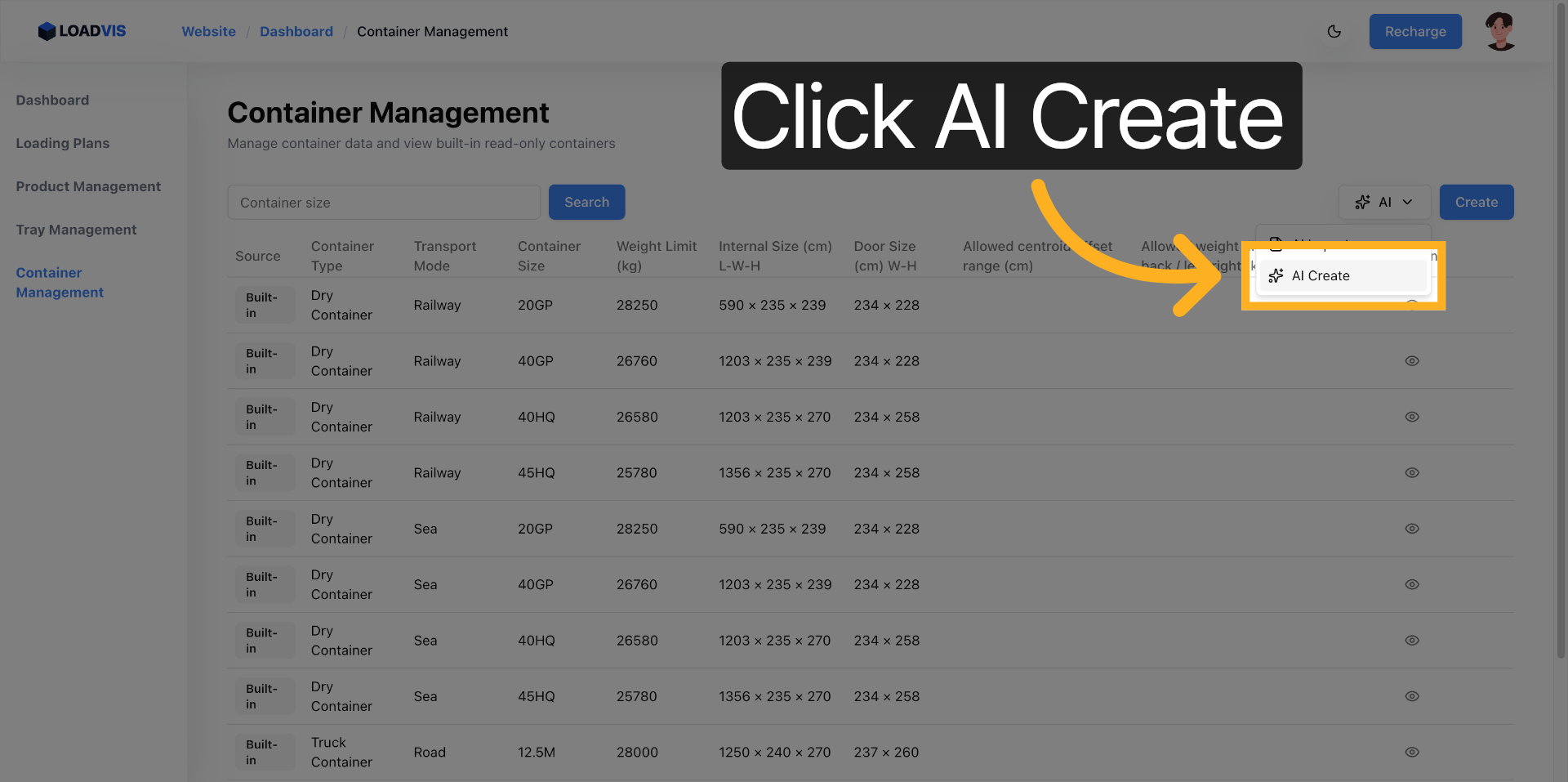
 워크스페이스 접근 및 AI 파싱 트리거
컨테이너 관리 인터페이스로 진입하면, 내장된 인식 도구를 실행해 규격 텍스트를 구조화합니다. 여기서 끝내면 안 됩니다. 파싱은 시작일 뿐입니다.
워크스페이스 접근 및 AI 파싱 트리거
컨테이너 관리 인터페이스로 진입하면, 내장된 인식 도구를 실행해 규격 텍스트를 구조화합니다. 여기서 끝내면 안 됩니다. 파싱은 시작일 뿐입니다.
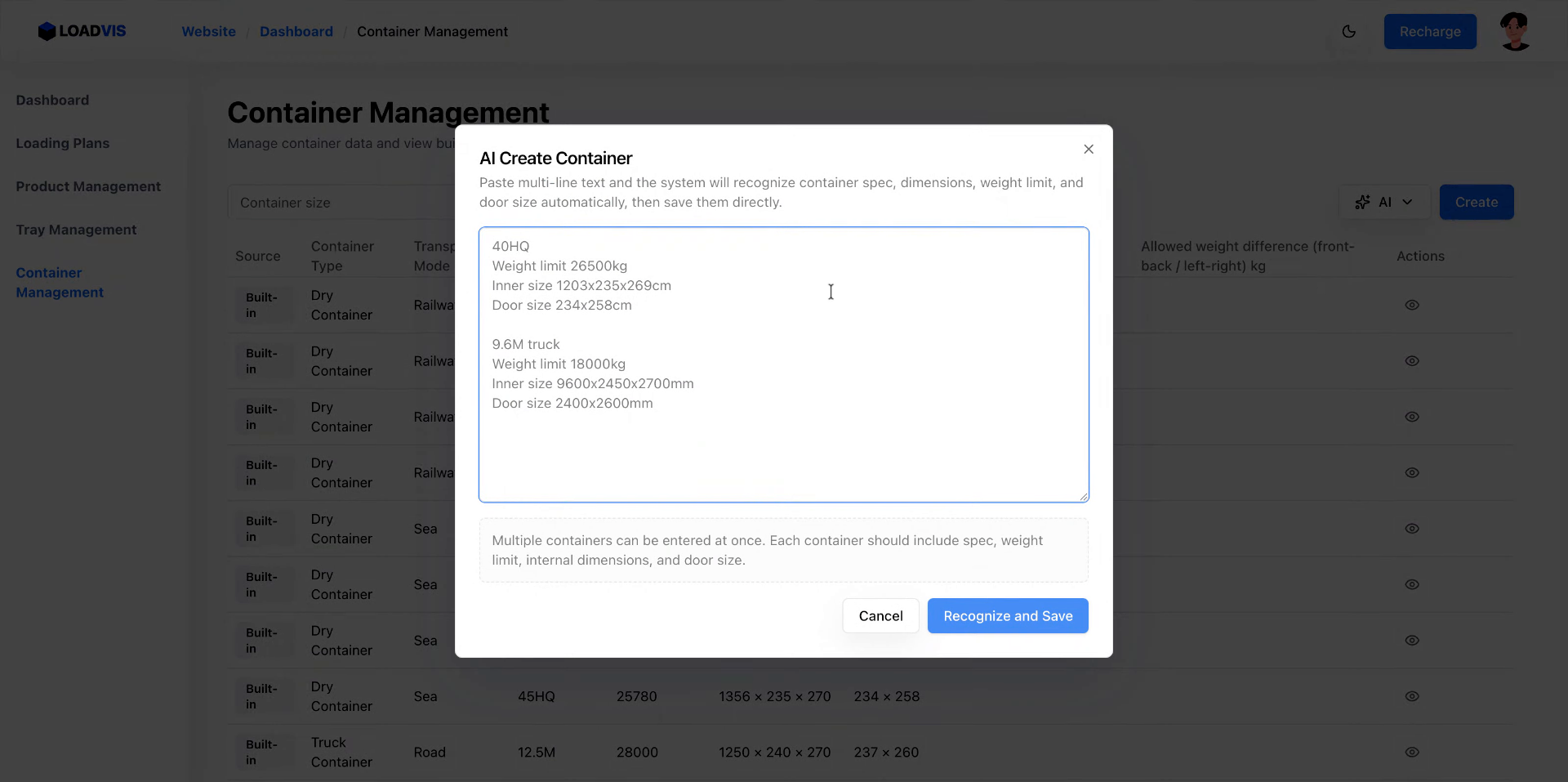
 비정형 명세서에서 매개변수 분리 추출
입력 필드에 "20OT 최대 중량: 21,500kg 내부 치수: 589×232×233cm 도어 개구부: 233×223cm"과 같은 원문을 그대로 던집니다. 시스템이 각 변수를 분리하지만, 파싱된 숫자는 여전히 '이론값'입니다.
비정형 명세서에서 매개변수 분리 추출
입력 필드에 "20OT 최대 중량: 21,500kg 내부 치수: 589×232×233cm 도어 개구부: 233×223cm"과 같은 원문을 그대로 던집니다. 시스템이 각 변수를 분리하지만, 파싱된 숫자는 여전히 '이론값'입니다.
2. 실운영 중량 보정 AI가 텍스트에서 21,500kg을 추출했다면, 이를 그대로 저장하기보다 현장 안전 규정 및 운송 수단 제한치(예: 21,000kg)로 하향 조정하는 편집 과정이 필요합니다. 알고리즘은 입력된 숫자를 절대값으로 처리하므로, 입력 단계에서의 현실 보정이 최종 결과의 안전성을 좌우합니다.
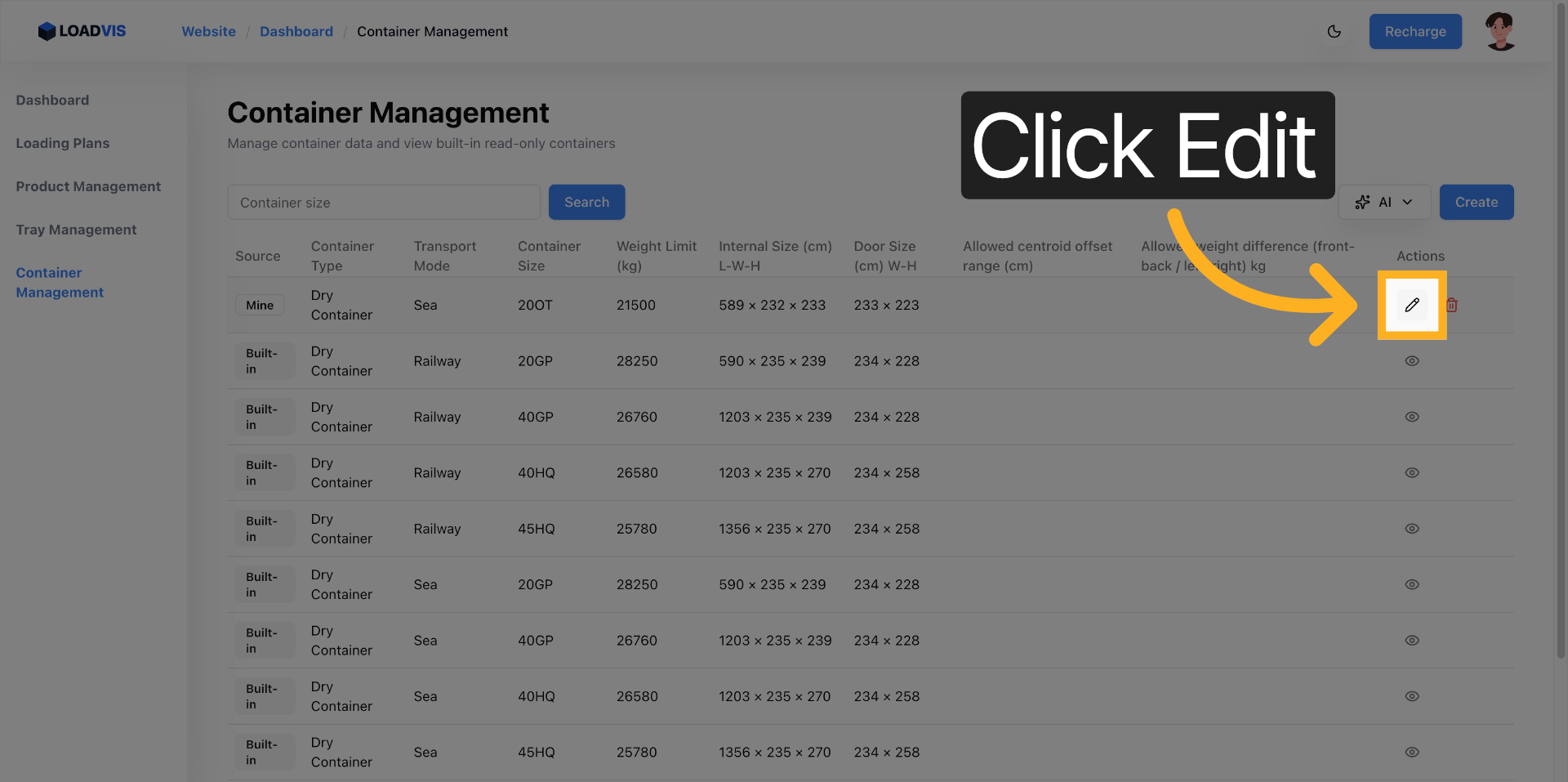
 추출값의 2차 교차 확인
인식 버튼을 누르기 전, 필드별로 커서를 두고 수치를 훑어봐야 합니다. 매뉴얼상의 최대치와 실제 운용 제한치는 다릅니다. 편집 모드로 진입해 적재 한도나 문 개구부 높이를 현장 측정치로 직접 덮어쓰는 과정이 반드시 동반되어야 합니다.
추출값의 2차 교차 확인
인식 버튼을 누르기 전, 필드별로 커서를 두고 수치를 훑어봐야 합니다. 매뉴얼상의 최대치와 실제 운용 제한치는 다릅니다. 편집 모드로 진입해 적재 한도나 문 개구부 높이를 현장 측정치로 직접 덮어쓰는 과정이 반드시 동반되어야 합니다.
 수동 보정을 통한 변수 재조정
수동 보정을 통한 변수 재조정
3. 저장 전 유효성 교차 검증 인식 및 저장 버튼을 누르기 전, 파싱된 값이 실제 운용 중인 컨테이너 Fleet의 상태와 일치하는지 확인하는 단계가 필수적입니다. 이 과정은 알고리즘이 '가능한 배치'가 아닌 '실행 가능한 배치'를 계산하도록 하는 안전장치입니다.
 보정 완료 후 데이터베이스 반영
모든 필드의 교차 검증이 끝나야 저장 로직이 작동합니다. 목록이 새로 고쳐진 시점부터, 해당 컨테이너는 시뮬레이션 엔진의 신뢰할 수 있는 제약 조건으로 등록됩니다.
보정 완료 후 데이터베이스 반영
모든 필드의 교차 검증이 끝나야 저장 로직이 작동합니다. 목록이 새로 고쳐진 시점부터, 해당 컨테이너는 시뮬레이션 엔진의 신뢰할 수 있는 제약 조건으로 등록됩니다.
잘못된 접근 방식 vs 더 확실한 방법
- 잘못된 접근: 표준 템플릿을 그대로 사용하거나, AI 파싱 결과값을 검증 없이 즉시 저장함. 도어 치수와 내부 치수를 혼용하거나, 중량 한계를 이론적 최대치로 고정함. 결과적으로 적재 시퀀스가 꼬이거나, 현장 하역 시 물리적 충돌 및 안전 사고 위험이 증가함.
- 더 확실한 방법: AI 파싱 또는 Excel 가져오기 후 반드시 '편집' 단계로 진입하여 도어 개구부, 내부 유효 치수, 실제 운영 중량 한계를 현장 측정치 또는 내부 SOP와 교차 검증함. 컨테이너 노후화나 전용 화물 특성에 맞춰 매개변수를 커스터마이징하고, 변경 이력을 체계적으로 관리함.
도구가 어디까지 도울 수 있는지, 여전히 수작업 확인이 필요한 단계
컨테이너 관리 기능은 비정형 텍스트나 명세서를 구조화하여 데이터베이스에 저장하고, 계산 엔진이 이 제약 조건을 기반으로 3D 배치와 중량 분포를 시뮬레이션하는 데 최적화되어 있습니다. 반복적인 입력 오류를 줄이고, 팀 내 데이터 표준화를 가능하게 하는 것이 도구의 명확한 역할입니다. 그러나 다음 단계는 소프트웨어가 아닌 현장의 물리적 검증이 반드시 필요합니다.
- 실제 구조물 상태 확인: 도어 프레임 미세 변형, 바닥 패널 마모, 보강재 돌출 부위는 데이터로 입력되지 않습니다. 현장 실측 또는 사진 검증이 병행되어야 합니다.
- 하역 환경 변수: 현장 크레인/포크리프트의 실제 회전 반경, 도크 레벨 높이, 작업자 안전 거리 등 환경적 제약은 외부 입력 또는 현장 조정으로 보완해야 합니다.
- 화물 고유의 변수: 유연한 포장재의 팽창, 불규칙형 화물의 실제 무게중심, 고정 장비(스트랩, 목재 블록) 점유 공간은 계획 실행 전 최종 확인 단계에서 처리해야 합니다.
데이터의 정확성은 알고리즘의 연산 속도를 결정하지 않습니다. 입력된 전제 조건이 현장의 물리적 한계를 얼마나 충실히 반영하느냐가 실행 가능 여부를 결정합니다. 컨테이너 관리 단계는 계산을 위한 룰셋을 정교하게 다듬는 과정이며, 현장의 경계를 데이터로 먼저 정의할 때 비로소 시뮬레이션과 실제 적재 사이의 간극은 좁아집니다. 툴이 만능 열쇠가 아니라는 점을 잊지 마세요. 그것은 거대한 현장 데이터를 구조화하는 프레임일 뿐입니다. 최종적인 '적합' 판정은 여전히 사람의 눈과 현장의 실측치에 달려 있습니다.